ORM框架-Hibernate
ORM 技术
ORM 是一种自动生成 SQL 语句的技术,它可以将对象中的数据自动存储到数据库中,也可以反过来将数据库中的数据自动提取到对象中,整个过程不需要人工干预,避免了手写 SQL 带来的麻烦。
JPA
2006年,J2EE5.0标准正式发布以后,持久化框架标准Java Persistent API(简称JPA)基本上是参考Hibernate实现的,而Hibernate在3.2版本开始,已经完全兼容JPA标准。
JPA 最初由SUN公司推出的基于ORM的规范,内部由一系列接口和抽象类组成。Hibernate ORM 5.x 框架 使用 JPA 2.2 实现。
实现JPA 规范的框架有多个:
Hibernate
Hibernate 是 Gavin King 和他的开发团队在 2001 年推出一个开源免费的、基于 ORM 技术的 Java 持久化框架。
Hibernate 将 Java 对象与数据库表之间建立起映射关系,并提供了一系列数据访问接口,Java 开发人员可以通过这些接口随心所欲地使用面向对象思想对数据库进行操作。
Hibernate 框架具有良好的可移植性,它支持几乎所有主流的关系型数据库,例如 MySQL、Oracle、SQL Server和 DB2 等等,开发人员只要在配置文件中指定好当前使用的数据库,就不需要操心不同数据库之间的差异。
Hibernate 是一款全自动的 ORM 框架,它能够自动生成的 SQL 语句并自动执行,实现对数据库进行操作,整个过程完全不需要人工干预,大大降低了开发成本。
Hibernate VS MyBatis
Hibernate 是一款全自动的 ORM 框架。之所以将 Hibernate 称为全自动的 ORM 框架,这其实是相对于 MyBatis 来说的。
我们知道,ORM 思想的核心是将 Java 对象与数据表之间建立映射关系。所谓的映射关系,简单点说就是一种对应关系,这种对应关系是双向的:
- 将数据表对应到 Java 对象上,这样数据表中的数据就能自动提取到 Java 对象中;
- 将 Java 对象对应到数据表上,这样 Java 对象中的数据就能自动存储到数据表中。
MyBatis 虽然是一种 ORM 框架,但它建立的映射关系是不完整的。Mybatis 只能将数据表映射到 Java 对象上,却不能将 Java 对象映射到数据表上,所以数据只能从数据表自动提取到 Java 对象中,反之则不行。要想将 Java 对象中的数据存储数据表中,开发人员需要手动编写 SQL 语句,依然非常麻烦,这就是 MyBatis 被称为半自动 ORM 框架的原因。
与 MyBatis 相比,Hibernate 建立了完整的映射关系,它不仅能将数据表中的数据自动提取到 Java 对象中,还能自动生成并执行 SQL 语句,将 Java 对象中的数据存储到数据表中,整个过程不需要人工干预,因此 Hibernate 被称为全自动的 ORM 框架。
配置
Hibernate 的常用配置文件有 2 种:核心配置文件(hibernate.cfg.xml)和映射文件(xxx.hbm.xml)
在Spring 框架中,hibernate.cfg.xml 配置文件不是必须的,因为可以通过Java Config的方式进行配置。
在 EntityMode=POJO 的配置下(默认),映射文件也不是必须的,可以在实体类上通过注解的方式配置。
核心配置文件
Hibernate 需要设置的配置参数在 org.hibernate.cfg.AvailableSettings 中可以找到
hibernate:
mappingLocations:
- classpath*:/config/*.hbm.xml
- classpath*:/config/hbm/*.xml
packagesToScan:
- com.beecode.bap.scheduler.entity
- com.beecode.inz.projectcheck.entity
- com.beecode.inz.creditrating.entity
properties:
hibernate.hbm2ddl.auto: update
hibernate.dialect: org.hibernate.dialect.MySQL57Dialect
hibernate.dialect.storage_engine: innodb
#hibernate.show_sql: true
hibernate.multiTenancy: schema
hibernate.enable_lazy_load_no_trans: true方言
Hibernate 可移植性好,能够屏蔽不同数据库之间的差异。当需要更换数据库时,通常只需要修改其配置文件(hibernate.cfg.xml)中的 hibernate.dialect(方言) 属性,指定数据库类型即可,Hibernate 会根据指定的方言自动生成对应的 SQL 语句。
org.hibernate.dialect.MySQL57Dialect管理Session的上下文
hibernate.current_session_context_class 是HibernateProperties的一个配置参数,用于指定Hibernate如何管理Session的上下文。它的可选值有三个:
- thread:使用线程绑定的Session上下文。这意味着每个线程都会有一个自己的Session实例,线程之间的Session实例不会相互干扰。
- jta:使用JTA事务上下文。在使用Java事务API(JTA)进行分布式事务管理时,需要将此值设置为jta。
- managed:由容器管理Session上下文。这意味着Session实例将由容器自动管理,而不需要手动管理。
默认情况下,Hibernate会使用thread作为当前会话上下文类,这意味着每个线程都会有自己的Session实例。在大多数情况下,这是一个很好的选择,因为它很简单并且易于使用。但是,在使用JTA进行分布式事务管理时,需要将此值设置为jta,以便Hibernate能够正确地与JTA集成。如果使用Spring或其他容器,则可以将此值设置为managed,以便让容器来管理Session上下文。
三种策略都实现了 CurrentSessionContext 接口。
配置参数
AvailableSettings类枚举了Hibernate所理解的所有配置属性。
映射文件
Hibernate 映射文件用于在实体类对象与数据表之间建立映射关系。
映射类型
基本类型
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| byte | byte 或 java.lang.Byte | TINYINT |
| short | short 或 java.lang.Short | SMALLINT |
| integer | int 或 java.lang.Integer | INTEGER |
| long | long 或 java.lang.Long | BIGINT |
| float | float 或 java.lang.Float | FLOAT |
| double | double 或 java.lang.Double | DOUBLE |
| character | java.lang.String | CHAR(1) |
| boolean | boolean 或 java.lang.Boolean | BIT |
| string | java.lang.String | VARCHAR |
| big_decimal | java.math.BigDecimal | NUMERIC |
日期和时间类型
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| date | java.util.Date 或 java.sql.Date | DATE |
| time | java.util.Date 或 java.sql.Time | TIME |
| timestamp | java.util.Date 或 java.sql.Timestamp | TIMESTAMP |
| calendar | java.util.Calendar | TIMESTAMP |
| calendar_date | java.util.Calendar | DATE |
二进制和大型数据对象
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| binary | byte[] | VARBINARY (or BLOB) |
| text | java.lang.String | CLOB |
| serializable | any Java class that implements java.io.Serializable | VARBINARY (or BLOB) |
| clob | java.sql.Clob | CLOB |
| blob | java.sql.Blob | BLOB |
JDK 相关类型
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| class | java.lang.Class | VARCHAR |
| locale | java.util.Locale | VARCHAR |
| timezone | java.util.TimeZone | VARCHAR |
| currency | java.util.Currency | VARCHAR |
不写映射文件
Hibernate可以不写映射文件,特别是从JAVA5.0之后,可以利用注解来简化配置。简单来说就是不再需要映射文件了,hibernate需要的元数据(metadata)通过注解实体类就行了。然而,这并不意味着所有的开发者都应该放弃使用映射文件。因为对于一些复杂的多表关系,手动编写代码可能会带来不必要的困扰和错误。此外,使用映射文件可以使框架更加清晰,有利于代码的维护和理解。所以在实际的开发过程中,选择使用注解还是映射文件,需要根据实际情况和项目需求来决定。
注:不写映射文件的情况下,Entity Java类需要添加相应的注解,并且所在的包需要被hibernate扫描到。hibernate.packagesToScan
XSD 定义
Hibernate 映射文件是XML格式的,包含的元素非常多,有哪些元素和属性,怎么写,最直接的方式是查询XSD文件,在映射文件的头部已经声明了hibernate-mapping-4.0.xsd文件的位置。
示例:
如果想定义一个字符串类型的列,并设置长度,以下两种写法都可以:
<!-- 写法1 -->
<property name="certCode" type="string">
<column name="cert_code" length="100"></column>
</property>
<!-- 写法2 -->
<property name="certCode" type="string" column="cert_code" length="100"></property>但如果想给该字段加列注释,只能使用下面这种写法,因为XSD中定义的property 元素没有comment 属性和子元素,所以只能通过column 元素的子元素声明列注释。
<property name="certCode" type="string">
<column name="cert_code" length="100">
<comment>产证编号</comment>
</column>
</property>核心接口
Hibernate 中有 5 个常用的核心接口,它们分别是 :
- Configuration
- SessionFactory
- Session
- Transaction
- Query
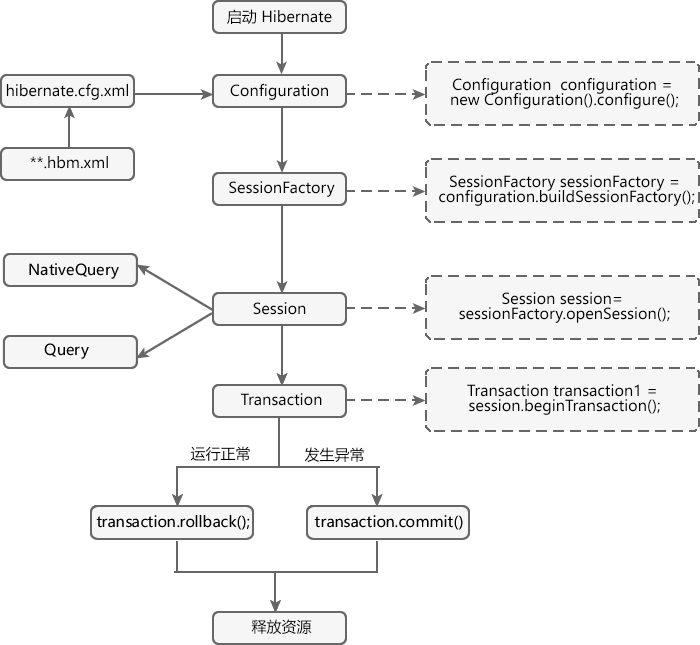
Configuration
SessionFactory
org.hibernate.Session 实例的工厂。
SessionFactory 的创建成本非常高,因此,对于任何给定的数据库,应用程序应该只有一个关联的 SessionFactory。SessionFactory 维护 Hibernate 在所有会话中使用的服务,例如二级缓存、连接池、事务系统集成等。
Session
Hibernate 中的会话表示应用程序和数据存储之间的对话。
Session 是单线程、短暂的对象,在概念上模拟“工作单元”(PoEAA)。在 Jakarta Persistence 命名法中,Session 由 EntityManager 表示。
在后台,Hibernate Session 包装 JDBC java.sql.Connection 并充当 org.hibernate.Transaction 实例的工厂。它维护应用程序域模型的一般“可重复读取”持久性上下文(第一级缓存)。
Session 是Hibernate 的主要运行时接口,是一个核心 API 类,Session 的主要功能是为映射实体类的实例提供增删改查操作。实例可能存在于以下三种状态之一:
- transient:从不持久化,不与任何Session关联
- persistent:与唯一的 Session 相关联
- detached:以前是持久的,不与任何 Session 关联
注:三种状态之间的转换关系,会在下面下面映射实体类时详细说明
获取Session
public void demo(){
Session sess = factory.openSession();
Transaction tx;
try {
tx = sess.beginTransaction();
//do some work...
tx.commit();
}catch (Exception e) {
if (tx!=null) tx.rollback();
throw e;
} finally {
sess.close();
}
}Session 的生命周期受限于逻辑事务的开始和结束。 (长事务可能跨越多个数据库事务。)
public interface Session {
/** 将持久化对象刷新到数据库*/
void flush();
/** 设置刷新时机 */
void setFlushMode(FlushMode var1);
void refresh(Object var1);
void persist(Object var1);
Serializable save(Object var1);
void update(Object var1);
void saveOrUpdate(Object var1);
Object merge(Object var1);
void delete(Object var1);
}刷新模式
Hibernate的FlushMode(刷新模式)定义了在何时将持久化上下文中的操作同步到数据库中。它控制了Hibernate的自动刷新行为。
Hibernate的FlushMode有以下几种模式:
AUTO(默认模式):在事务提交、查询执行之前或手动调用
flush()方法时,自动将持久化上下文中的操作刷新到数据库。也就是说,当需要执行查询操作或手动控制刷新时,会先自动执行刷新操作。COMMIT:只有在事务提交时才会刷新持久化上下文中的操作到数据库,对于查询操作不会自动执行刷新。这意味着,在事务提交之前,对持久化上下文的更改不会立即同步到数据库,而是延迟到事务提交时才执行。
MANUAL:完全手动控制刷新操作。Hibernate不会自动将持久化上下文中的操作刷新到数据库,需要手动调用
flush()方法来执行刷新操作。这样可以提供更高的灵活性,但也需要开发者自行负责控制刷新的时机。
通过设置FlushMode,可以根据业务需求来调整Hibernate的刷新行为,以提高性能或满足特定的数据一致性要求。常见的设置方式包括:
// 设置FlushMode为AUTO
session.setFlushMode(FlushMode.AUTO);
// 设置FlushMode为COMMIT
session.setFlushMode(FlushMode.COMMIT);
// 设置FlushMode为MANUAL
session.setFlushMode(FlushMode.MANUAL); 需要注意的是,FlushMode是与特定会话(Session)相关的设置。在使用Hibernate时,可以根据具体需求选择合适的FlushMode,并根据需要进行调整。
缓存模式
Hibernate的CacheMode(缓存模式)定义了在执行查询时如何使用和管理查询缓存。它控制了Hibernate的查询缓存的行为。
Hibernate的CacheMode有以下几种模式:
GET(默认模式):在执行查询时,尝试从查询缓存中获取结果。如果缓存中存在结果,则直接返回缓存的结果;否则,执行数据库查询并将结果存入缓存中。
IGNORE:忽略查询缓存,直接执行数据库查询,并不将结果存入查询缓存中。每次查询都会直接查询数据库,不使用缓存。
NORMAL:根据缓存策略决定是否使用查询缓存。如果查询的实体或集合配置了查询缓存策略(例如使用
@Cacheable注解),则使用查询缓存;否则,直接查询数据库。PUT:将查询结果存入查询缓存中,无论缓存中是否已存在相同查询的结果。如果缓存中已存在相同查询的结果,将会被新的结果覆盖。
通过设置CacheMode,可以根据需求来控制查询缓存的使用和管理方式。常见的设置方式包括:
// 设置CacheMode为GET
query.setCacheMode(CacheMode.GET);
// 设置CacheMode为IGNORE
query.setCacheMode(CacheMode.IGNORE);
// 设置CacheMode为NORMAL
query.setCacheMode(CacheMode.NORMAL);
// 设置CacheMode为PUT
query.setCacheMode(CacheMode.PUT); 需要注意的是,CacheMode是与特定查询(Query)相关的设置。在使用Hibernate时,可以根据具体需求选择合适的CacheMode,并根据需要进行调整。同时,还需要在实体或集合上配置合适的查询缓存策略,以使查询缓存生效。
更新快照
hibernate通过缓存和快照机制,实现对修改内容批量提交。
当查询DB时,会将数据保存到session缓存中,同时在内存中存储一份快照副本。
当我修改数据时,其实修改的是session缓存中的实体内容,并不立即提交DB执行。
当我们主动flush或提交事物时,会对比session缓存与快照中的内容是否一致,将不一致的内容更新到DB中。
refresh()方法
查询实体
在Hibernate中,Session的load、get和find方法都用于从数据库中获取实体对象,但它们在使用方式和行为上有一些区别。
session.get(entityClass, id)
session.find(entityClass, id)
session.load(entityClass, id)load方法:
- 懒加载(Lazy Loading):
load方法返回一个代理对象,只有在访问实际属性时才会发出数据库查询,延迟加载实体对象的属性。 - 若对象不存在:如果对象不存在于数据库中,则抛出
ObjectNotFoundException异常。 - 返回类型:返回的是代理对象,非空。
- 适用场景:适用于根据主键(ID)加载实体对象,且期望使用延迟加载来提高性能。
get方法:
- 立即加载(Eager Loading):
get方法立即从数据库中加载实体对象及其关联对象的所有属性。 - 若对象不存在:如果对象不存在于数据库中,则返回
null。 - 返回类型:返回的是实际的实体对象或
null。 - 适用场景:适用于根据主键(ID)加载实体对象,并立即获取完整的实体对象及其关联对象的属性。
find方法:
- 使用JPQL或Criteria查询:
find方法使用JPQL(Java Persistence Query Language)或Criteria查询语句从数据库中加载实体对象。 - 若对象不存在:如果对象不存在于数据库中,则返回
null。 - 返回类型:返回的是实际的实体对象或
null。 - 适用场景:适用于根据条件查询加载实体对象,可以使用灵活的JPQL或Criteria查询来过滤和排序结果。
总结:
load方法是懒加载,返回代理对象,适用于根据主键延迟加载实体对象的场景。get方法是立即加载,返回实际的实体对象或null,适用于根据主键立即获取完整实体对象的场景。find方法使用JPQL或Criteria查询,返回实际的实体对象或null,适用于根据条件查询加载实体对象的场景。
需要根据具体的需求和业务场景选择适当的方法来加载实体对象。
更新实体
在Hibernate中,merge()和update()方法都用于更新数据库中的实体对象。它们的主要区别如下:
merge()方法是将传入的对象的状态合并到持久化上下文中的对象,或者在持久化上下文中创建一个新的对象并将传入对象的状态复制到新对象中。它会返回持久化后的对象,可以用于后续操作。如果传入的对象是一个临时对象(transient),merge()方法会尝试将其关联到持久化上下文中,并返回一个持久化后的对象。如果传入的对象是一个游离对象(detached),则会将其复制到持久化上下文中并返回一个持久化后的对象。update()方法是将传入的对象的状态更新到数据库中对应的记录。它要求传入的对象必须是一个持久化状态的对象,即与数据库中的记录关联。如果传入的对象是一个临时对象或游离对象,update()方法会抛出异常。update()方法不返回任何结果。merge()方法可以在任何时候调用,无论对象是临时对象、游离对象还是持久化对象。它可以用于对象的合并、关联或更新操作。merge()方法会根据对象的标识属性来决定是合并到现有对象还是创建新的对象。update()方法只能用于持久化状态的对象,并且要求对象与数据库中的记录关联。如果对象与数据库中的记录不一致,会导致异常。
总的来说,merge()方法更加灵活,可以用于对象的合并和更新操作,并且可以在任何时候调用。而update()方法只能用于持久化状态的对象的更新操作,并且要求对象与数据库中的记录关联。选择使用哪个方法取决于你的具体需求和使用的框架。
在Hibernate中,persist()和save()方法都可以用于将一个新的实体对象持久化到数据库中。它们的主要区别在于以下几点:
persist()方法是JPA规范中定义的方法,而save()方法是Hibernate特定的方法。因此,persist()方法更符合JPA规范,而save()方法是Hibernate提供的一种更具有灵活性和扩展性的方法。persist()方法将实体对象持久化到数据库中,但不保证立即执行数据库操作。它会将实体对象添加到Hibernate的持久化上下文中,等待事务提交或者Flush操作时才会执行实际的数据库插入操作。如果在持久化上下文之外进行修改,对该实体的更改将不会被保存到数据库。save()方法立即执行数据库插入操作,将实体对象持久化到数据库中。它会立即执行INSERT语句,并返回持久化后的实体对象的标识。如果在持久化之前对实体对象进行修改,这些更改将被保存到数据库。persist()方法在持久化上下文中管理实体对象的生命周期,与其他已被持久化的实体对象进行关联。如果传递给persist()方法的实体对象已经是持久化状态,则该方法不会有任何效果。save()方法可以在持久化上下文之外使用,不受持久化上下文的管理。它可以强制执行数据库插入操作,即使实体对象已经是持久化状态。
综上所述,persist()方法更适合符合JPA规范的应用程序,并且更加注重与持久化上下文的管理。而save()方法则更具灵活性,可以在需要时立即执行数据库操作,适合一些特定的业务需求。选择使用哪个方法取决于你的具体需求和使用的框架。
锁定实体
在Hibernate中,Session的lock方法用于显式地锁定实体对象,控制并发访问和并发更新的行为。
lock方法的使用方式如下:
session.lock(entity, lockMode);其中,entity是要锁定的实体对象,lockMode是锁定模式。锁定模式可以是以下之一:
LockMode.NONE:不进行任何锁定。LockMode.READ:对实体对象进行读锁定。LockMode.UPGRADE:对实体对象进行升级锁定。LockMode.UPGRADE_NOWAIT:对实体对象进行升级锁定,如果锁不可用,则立即返回。LockMode.UPGRADE_SKIPLOCKED:对实体对象进行升级锁定,跳过已经被锁定的实体对象。LockMode.WRITE:对实体对象进行写锁定。
使用lock方法可以实现以下功能:
- 悲观锁(Pessimistic Locking):通过锁定实体对象,防止其他事务对该实体对象进行修改,从而确保数据的一致性和完整性。
- 并发控制:通过锁定实体对象,控制多个事务对同一实体对象的并发访问和更新行为,避免并发冲突和数据不一致的问题。
- 锁超时:某些锁定模式(例如
UPGRADE_NOWAIT)可以设置锁超时时间,在指定时间内尝试获取锁定,若锁不可用则立即返回。
需要注意的是,使用lock方法需要在事务环境中进行,即在已开启的事务中执行。此外,锁定对象必须是持久化状态的实体对象,而不是临时对象或游离对象。
示例代码:
Session session = sessionFactory.getCurrentSession();
Transaction transaction = session.beginTransaction();
try {
// 锁定实体对象
User user = session.get(User.class, userId);
session.lock(user, LockMode.UPGRADE);
// 执行业务逻辑
// ...
transaction.commit();
} catch (Exception e) {
transaction.rollback();
throw e;
}在上述示例中,通过lock方法将User实体对象进行升级锁定,以确保在事务中对该实体对象的操作不会被其他事务干扰。
使用lock方法可以在特定场景下实现精确的并发控制和数据访问控制,但需要注意锁定的粒度和锁定时间,避免出现死锁或性能问题。
Transaction
事务与会话相关联,通常通过调用 org.hibernate.Session.beginTransaction() 来启动。单个会话可能跨越多个事务,因为会话的概念比事务的概念具有更粗的粒度。但是,在任何时候,与指定会话相关联的事务最多只有一个未提交的事务。
Query
通过Session 获取Query接口:
/** 创建HQL查询*/
Query createQuery(String var1);
/** 创建命名的HQL查询:映射文件中定义查询语句*/
Query getNamedQuery(String var1);
/** 创建原生SQL查询*/
NativeQuery createSQLQuery(String var1);query.getResultList();
query.getSingleResult();//如果返回结果为空,会报错;
query.uniqueResult();//返回结果大于1则报错当确定返回行数只有0或1个的时候,可以使用 query.uniqueResult(),返回结果大于1则报错:
org.springframework.dao.IncorrectResultSizeDataAccessException: query did not return a unique result: 2; nested exception is org.hibernate.NonUniqueResultException: query did not return a unique result: 2命名查询
在Hibernate中,你可以使用@NamedQuery和@NamedQueries注解为实体类定义命名查询(Named Query)。命名查询是预定义的查询语句,它们在应用程序中可以通过名称来引用,而不是直接在代码中写查询语句。
@NamedQuery 注解
@NamedQuery注解用于在实体类上定义单个命名查询。你可以将它添加到实体类的注解中,并在该注解中指定查询的名称和查询语句。
javaCopy code@Entity
@NamedQuery(
name = "findEmployeeByName",
query = "SELECT e FROM Employee e WHERE e.name = :name"
)
public class Employee {
// Entity mapping and other fields/methods
}@NamedQueries 注解
@NamedQueries注解用于在实体类上一次性定义多个命名查询。你可以通过这个注解的@NamedQuery数组属性来定义多个命名查询。
@Entity
@NamedQueries({
@NamedQuery(
name = "findEmployeeByName",
query = "SELECT e FROM Employee e WHERE e.name = :name"
),
@NamedQuery(
name = "findAllEmployees",
query = "SELECT e FROM Employee e"
)
})
public class Employee {
// Entity mapping and other fields/methods
}使用 session.createNamedQuery 方法查询:
public UserEntity findByPhoneNumber(String phoneNumber) {
return template.execute(session -> session.createNamedQuery("com.jiuqi.np.user.entity.UserEntity.findByPhoneNumber", UserEntity.class)
.setParameter("telephone", phoneNumber).uniqueResult());
}除了可以在实体类中定义明明查询,映射文件中同样可以定义:
<class name="com.jiuqi.np.user.entity.UserEntity" table="np_user">
<id name="id" type="java.util.UUID">
<column name="id" length="16" />
<generator class="uuid2" />
</id>
<property name="name" unique="true" type="nstring">
<column name="name" length="50" />
</property>
<query name="findByPhoneNumber"><![CDATA[from com.jiuqi.np.user.entity.UserEntity where telephone = :telephone]]></query>
</class>限制查询条目
hql 中使用 limit 会报错
正确的方式是使用 API的方式限制查询条数
//设置开始位置
setFirstResult(0)
//设置最大条数
setMaxResult(1)hbm.xml
| 属性 | 值 | 描述 |
|---|---|---|
| length | 数字 | 字段长度 |
| precision | 数字 | 精度(decimal precision) |
| scale | 数字 | 小数点位数(decimal scale) |
| not-null | true|false | 指明字段是否应该是非空的 |
| unique | true |false | 指明是否该字段具有惟一约束 |
| index | index_name | 指明一个(多字段)的索引(index)的名字 |
| unique-key | unique_key_name | 指明多字段惟一约束的名字 |
| foreign-key | foreign_key_name | 指明一个外键的名字,它是为关联生成的 |
| default | SQL 表达式 | 为字段指定默认值 |
| check | SQL 表达式 | 对字段或表加入 SQL 约束检查 |
HQL 语法
HQL 语言有点像SQL,但又不同,HQL 是特意被设计为完全面向对象的查询,它可以理解如继承、多态、关联之类的概念。
博客地址:
https://docs.jboss.org/hibernate/orm/3.5/reference/zh-CN/html/index.html
https://docs.jboss.org/hibernate/orm/3.5/reference/zh-CN/html/queryhql.html
form 子句
from Cat
from Cat as catpublic BigDecimal getRefundNumberByContractId(String contractId) {
String hql ="select sum(adjust.sum) from com.beecode.inz.contract.datamodel.AdjustOrder adjust "
+"where contract.id=:contractId";
return template.execute((session)-> {
Query<BigDecimal> query = session.createQuery(hql);
query.setParameter("contractId", uuid);
return query.getSingleResult();
});
}返回结果封入自定义对象
指定 select 查询列,将返回结果封入自定义对象,这种用法也很方便,前提是自定义的Pojo 必须含有所需要属性的构造函数:
public List<AssetsUseDetailPojo> queryAssetsUseDetailByAssetId(UUID assetId) {
String queryLeaseInfoByAssetHql = "select new com.beecode.inz.contract.pojo.AssetsUseDetailPojo(contract.title as contractName, contract.customer.name as customerName,startDate,endDate,rentPrice) from com.beecode.inz.contract.datamodel.AssetsUseDetail where asset.id=:assetId order by startDate";
return template.execute(session->{
Query<AssetsUseDetailPojo> createQuery = session.createQuery(queryLeaseInfoByAssetHql,AssetsUseDetailPojo.class);
createQuery.setParameter("assetId", assetId);
return createQuery.getResultList();
});
}自定义的Pojo :
public class AssetsUseDetailPojo {
private String contractName;
private String customerName;
private Date startDate;
private Date endDate;
private BigDecimal rentPrice;
public AssetsUseDetailPojo() {
}
public AssetsUseDetailPojo(String contractName, String customerName, Date startDate, Date endDate,
BigDecimal rentPrice) {
super();
this.contractName = contractName;
this.customerName = customerName;
this.startDate = startDate;
this.endDate = endDate;
this.rentPrice = rentPrice;
}
//getter and setter ....
}返回结果封入Map
通常hibernate查询出的结果集是 List
public void demo1(){
//结果list中,每条记录对应一个map,map中key为hql语句中的序号,从0开始,key为字符,非数字。
String hql="select new map(s.name) from Student s";
List ls = session.createQuery(hql).list();
for(Map m:ls){
System.out.pringln(m.get("0"));
}
}
public void demo2(){
//结果list中,每条记录对应一个map,map中key为hql语句中的别名。
String hql=“select new map(s.name as name) from Student s”;
List ls=session.createQuery(hql).list();
for(Map m:ls){
System.out.pringln(m.get("name"));
}
}注:hibernate对 select new map 类型的hql解析的时候,遇到map这个关键字,将后面的列作为值,别名作为键(若无别名,则用数字代替)存入到一个HashMap中。
元组 Tuple
public Object getLastLeaseInfoByAsset(UUID assetId,Date date) {
String hql = "select area as area,rent_price as rentPrice,days as days,start_date as startDate,end_date as endDate from ...";
return template.execute(session->{
NativeQuery<Tuple> nativeQuery = session.createNativeQuery(hql,Tuple.class);
nativeQuery.setParameter("assetId", assetId);
nativeQuery.setParameter("date", date);
Tuple uniqueResult = nativeQuery.uniqueResult();
BigDecimal area = uniqueResult.get("area", BigDecimal.class);
BigDecimal rentPrice = uniqueResult.get("rentPrice", BigDecimal.class);
return uniqueResult;
});
}public void demo{
//下面这3种写法是等价的;
(BigDecimal)tuple.get("rentPrice");
(BigDecimal)tuple.get(1); //下标从0开始
tuple.get("rentPrice", BigDecimal.class);
//同上
(byte[])tuple.get("contractId");
(byte[])tuple.get(1);
tuple.get("contractId", byte[].class);
}原生SQL
Hibernate 允许你使用原生SQL 来查询数据
需要注意的是,使用 createSQLQuery 时,返回的结果是一个 List<Object[]>,其中每个 Object[] 代表查询结果的一行,数组元素的顺序与查询选择的列的顺序相对应。
Query nativeQuery = session.createNativeQuery(hql);
nativeQuery.setParameter("assetId", assetId);
Object[] uniqueResult = (Object[]) nativeQuery.uniqueResult();
BigDecimal area = (BigDecimal)uniqueResult[0];方式二:转化为Map(最常用)
List<Map<String,Object>> result = template.execute(session -> {
NativeQuery query = session.createSQLQuery(sql);
if(unitCode!=null) query.setParameter("unitCode", unitCode);
query.setResultTransformer(Transformers.ALIAS_TO_ENTITY_MAP);
return query.getResultList();
});方式三:转化为Java类
public List<TestCto> demoSqlQuery(){
NativeQuery sqlQuery = session.createSQLQuery("SELECT * FROM CATS");
//调用addScalar, 说明取结果集里的哪些字段, 字段被映射为哪种类型
sqlQuery.addScalar("column1", Hibernate.LONG);
sqlQuery.addScalar("column2", Hibernate.STRING);
sqlQuery.addScalar("column3", Hibernate.STRING);
//设置将对象转化为Cto对象, 注意Cto对象的各属性类型要与addScalar里指明的一致
sqlQuery.setResultTransformer(Transformers.aliasToBean(TestCto.class));
return sqlQuery.list(); //返回TestCto的List列表
}分页
//设置取的结果集行数: 分页使用,可选
sqlQuery.setFirstResult((pageIndex-1) * pageSize); //pageIndex从1开始
sqlQuery.setMaxResults(pageSize);executeUpdate
使用Query接口的 executeUpdate 方法通过HQL执行增删改 操作。
public class EquipmentDaoImpl implements EquipmentDao {
@Autowired
private HibernateOperations template;
@Override
public int modifyEqptState(UUID eqptId, String eqptState) {
return template.execute(session ->{
String hql = "update datamodel.equipment set state =:state where id =:id";
Query<?> query = session.createQuery(hql);
query.setParameter("id", eqptId);
query.setParameter("state", eqptState);
return query.executeUpdate();
});
}
}持久化实体类
映射实体类的对象也叫持久化对象,(Persistent Object,简称 PO ),在 Hibernate 中, PO 是由 java实体类和 hbm 映射配置组成。
持久化对象”就是持久化类的实例对象,它与数据库表中一条记录相对应,Hibernate 通过操作持久化对象即可实现对数据库表的 CRUD 操作。
在 Hibernate 中,持久化对象是存储在一级缓存中的,一级缓存指 Session 级别的缓存,它可以根据缓存中的持久化对象的状态改变同步更新数据库,
三种状态
在进行数据持久化操作时,持久化对象可能处于不同的状态当中,这些状态可分为三种,分别为瞬时态、持久态和脱管态,如下表。
| 状态 | 别名 | 产生时机 | 特点 |
|---|---|---|---|
| 瞬时态(transient) | 临时态或自由态 | 由 new 关键字开辟内存空间的对象(即使用 new 关键字创建的对象) | 未与任何 Session 实例建立关联关系; 没有唯一标识 OID; 数据库中也没有与之相关的记录; |
| 持久态(persistent) | – | 当对象加入到 Session 的一级缓存中时,与 Session 实例建立关联关系时 | 已经纳入到 Session 中管理; 数据库中存在对应的记录; 存在唯一标识 OID,且不为 null; 持久态对象的任何属性值的改动,都会在事务结束时同步到数据库表中。 |
| 脱管态(detached) | 离线态或游离态 | 持久态对象与 Session 断开联系时 | 与 Session 断开关联关系,未纳入 Session 中管理; 存在唯一标识 OID; 一旦有 Session 再次关联该脱管对象,那么该对象就可以立马变为持久状态; 脱管态对象发生的任何改变,都不能被 Hibernate 检测到,更不能提交到数据库中。 |
在 Hibernate 运行时,持久化对象的三种状态可以通过 Session 接口提供的 一系列方法进行转换。这三种状态之间的转换关系具体如下图。

通过上图可知,持久化对象的状态转换遵循以下规则:
- 当一个实体类对象通过 new 关键字创建时,此时该对象就处于瞬时态。
- 当执行 Session 接口提供的 save() 或 saveOrUpate() 方法,将瞬时态对象保存到 Session 的一级缓存中时,该对象就从瞬时态转换为了持久态。
- 当执行 Session 接口提供的 evict()、close() 或 clear() 方法,将持久态对象与 Session 断开关联关系时,该对象就从持久态转换为了脱管态。
- 当执行 Session 接口提供的 update()、saveOrUpdate() 方法,将脱管态对象重新与 Session 建立关联关系时,该对象会从脱管态转换为持久态。
- 直接执行 Session 接口提供的 get()、load() 或 find() 方法从数据库中查询出的对象,是处于持久态的。
- 当执行 Session 接口提供的 delete() 方法时,持久态对象就会从持久态转换为瞬时态。
- 由于瞬时态和脱管态对象都不在 Session 的管理范围内,因此一段时间后,它们就会被 JVM 回收。
触发SQL的动作:
- save() 和 persist() 导致 SQL INSERT
- update() 或 merge() 导致 SQL UPDATE。
- delete() 导致 SQL DELETE
- saveOrUpdate() 和 replicate() 导致 INSERT 或 UPDATE。
- 持久实例的更改在刷新时被检测到,也会导致 SQL UPDATE。
实体继承
实体继承关系的映射策略共有三种:
- 单表继承策略(Single Table Inheritance)
- 表间继承策略(Table Per Class Inheritance)
- 联合继承策略(Joined Inheritance)
单表继承策略,
父类实体和子类实体分别对应数据库中不同的表,子类实体的表中只存在其扩展的特殊属性,父类的公共属性保存在父类实体映射表中。
Table_PER_CLASS策略,父类实体和子类实体每个类分别对应一张数据库中的表,子类表中保存所有属性,包括从父类实体中继承的属性。
<joined-subclass entity-name="com.beecode.inz.contract.datamodel.LeaseContract" table="inz_contract_lease_contract" extends="com.beecode.inz.contract.datamodel.Contract">JPA 定义了三种实体继承策略:
SINGLE_TABLE 单表继承
父类实体和子类实体共用一张数据库表,在表中通过一列辨别字段来区别不同类别的实体。JOINED 联合继承
父类和子类实体分别对应数据库中不同的表,子类实体的表中只存在其扩展的特殊属性,父类的公共属性保存在父类实体映射表中。父类与子类的关联字段是相同的(一般是ID)。
Table_PER_Class 表分离策略
父类和子类实体分别对应数据库中不同的表,子类表中保存所有属性,包括从父类实体中继承的属性。
使用方式
在父类实体上添加注解:
@Inheritance(Strategy=InheritanceType.TABLE_PER_CLASS)子类实体继承父类
表间继承 UNION
场景:
定义一个抽象父类,不生成物理表,定义子类,子表中存储父类和子类实体的所有属性。
定义抽象父类的实体类:
@MappedSuperclass
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public abstract class BillMasterBase extends BillEntityBase {
/** 创建时间 */
@Column(name = "create_time", nullable = false)
private Instant createTime;
...
}定义抽象父类的映射文件:
<?xml version="1.0" encoding="UTF-8"?>
<hibernate-mapping xmlns="http://www.hibernate.org/xsd/hibernate-mapping"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.hibernate.org/xsd/hibernate-mapping
http://www.hibernate.org/xsd/hibernate-mapping/hibernate-mapping-4.0.xsd">
<class entity-name="com.beecode.bap.bill.entity.BillMasterBase" abstract="true" table="bill_master" optimistic-lock="version">
<id name="id" type="uuid-binary" column="id" length="16"/>
<version name="recver" type="long"/>
<property name="createTime" type="Instant" column="create_time" index="_createtime_idx" />
...
</hibernate-mapping>定义子类的实体类:
@Entity
@Table(name = "T_BILL01")
public class TestBill01 extends BillMasterBase {
@Column(name = "message")
private String message;
}定义子类的映射文件:
<?xml version="1.0" encoding="UTF-8"?>
<hibernate-mapping xmlns="http://www.hibernate.org/xsd/hibernate-mapping"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.hibernate.org/xsd/hibernate-mapping
http://www.hibernate.org/xsd/hibernate-mapping/hibernate-mapping-4.0.xsd">
<union-subclass entity-name="com.beecode.bap.bill.test.entity.TestBill01" table="T_BILL01" extends="com.beecode.bap.bill.entity.BillMasterBase">
<tuplizer entity-mode="dynamic-map" class="com.beecode.bcp.store.hibernate.KObjectEntityTuplizer"/>
<property name="message" type="nstring" column="message" length="255"/>
<property name="intA" type="int" column="int_a"/>
...
</union-subclass>
</hibernate-mapping>联合继承 JOINED
定义父类的实体类:
@Entity
@Table(name = "t_k_base")
@Inheritance(strategy = InheritanceType.JOINED)
public class KBaseEntity {
@Id
private UUID id;
...
}定义父类的映射文件:
<?xml version="1.0" encoding="UTF-8"?>
<hibernate-mapping xmlns="http://www.hibernate.org/xsd/hibernate-mapping"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.hibernate.org/xsd/hibernate-mapping
http://www.hibernate.org/xsd/hibernate-mapping/hibernate-mapping-4.0.xsd">
<class entity-name="com.beecode.bcp.store.test.entity.KBaseEntity" table="t_k_base">
<id name="id" type="uuid-binary" column="id" length="16" />
<property name="name" type="nstring" column="name" length="50" />
<property name="title" type="nstring" column="title" length="100" />
<property name="code" type="int" column="code_0" />
</class>
</hibernate-mapping>定义子类的实体类:
@Entity
@Table(name = "t_k_ext01")
public class KExtEntity01 extends KBaseEntity {
@Column(name = "age_0")
private int age;
}定义子类的映射文件:
<?xml version="1.0" encoding="UTF-8"?>
<hibernate-mapping xmlns="http://www.hibernate.org/xsd/hibernate-mapping"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.hibernate.org/xsd/hibernate-mapping
http://www.hibernate.org/xsd/hibernate-mapping/hibernate-mapping-4.0.xsd">
<joined-subclass entity-name="com.beecode.bcp.store.test.entity.KExtEntity01" table="t_k_ext01" extends="com.beecode.bcp.store.test.entity.KBaseEntity">
<key column="id" />
<property name="age" type="int" column="age_0" />
<property name="address" type="nstring" column="addr" length="255" />
</joined-subclass>
</hibernate-mapping>HibernateProxy
HibernateProxy是Hibernate框架中的一个类,它是一个代理对象,用于延迟加载一个实体类的关联属性。
在Hibernate中,当实体类关联的数据较多时,为了避免一次性查询所有的数据导致性能问题,可以使用延迟加载的方式,即在需要使用关联属性时才去加载,而不是在查询实体类时就加载所有的关联属性。HibernateProxy就是用于实现这种延迟加载的代理对象。使用HibernateProxy的方式是,当查询到一个实体类时,如果该实体类有延迟加载的关联属性,则该关联属性会被代理成一个HibernateProxy对象。当需要使用该关联属性时,调用HibernateProxy的getTarget()方法就会触发实际的加载过程。
下面是一个示例:
// 查询一个User实体,该实体有一个延迟加载的Order集合属性
User user = session.get(User.class, 1L);
// 调用Order集合属性的方法时,会触发实际的加载过程
Set<Order> orders = user.getOrders();在上述代码中,当调用user.getOrders()方法时,由于Order集合属性是延迟加载的,因此会返回一个HibernateProxy代理对象。当需要使用Order集合属性时,如遍历集合或者调用集合的其他方法时,就会触发实际的加载过程,从数据库中加载相关的数据。
抽象继承
有一种业务场景,我们需要一个抽象父类实体,声明一些公共的属性,但又不希望有父类这张表,这种情况可以将父类声明为抽象的:
<?xml version="1.0" encoding="UTF-8"?>
<hibernate-mapping xmlns="http://www.hibernate.org/xsd/hibernate-mapping"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.hibernate.org/xsd/hibernate-mapping
http://www.hibernate.org/xsd/hibernate-mapping/hibernate-mapping-4.0.xsd">
<class entity-name="com.beecode.bap.bill.entity.BillMasterBase" abstract="true" table="bill_master" optimistic-lock="version">
<id name="id" type="uuid-binary" column="id" length="16"/>
<version name="recver" type="long"/>
<property name="createTime" type="Instant" column="create_time" index="_createtime_idx" />
...
</hibernate-mapping>禁止混合继承
在实体类继承关系中使用了混合的继承策略,这是不被支持的。Hibernate 将会抛出 org.hibernate.boot.MappingException: Mixed inheritance strategies not supported 异常。
下面是一个错误示范:
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public class Vehicle {
// ...
}
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
public class Car extends Vehicle {
// ...
}主键生成策略
在Hibernate中,@GeneratedValue 注解用于标记实体对象的主键生成策略,其中GenerationType是指定生成策略的一个枚举类型。以下是GenerationType 枚举类型中的选项及其含义:
- AUTO:由Hibernate自动选择适当的生成策略。这通常是根据数据库的类型和Hibernate方言来确定的。如果使用MySQL等数据库,则默认为IDENTITY策略;如果使用Oracle等数据库,则默认为SEQUENCE策略。
- IDENTITY:使用数据库自增长列来生成主键。对于MySQL、SQL Server和DB2等数据库,使用自增长列来生成主键是一个常见的方式。
- SEQUENCE:使用数据库序列来生成主键。序列是一种在数据库中生成唯一值的机制,可以在多个应用程序中共享,适用于Oracle、PostgreSQL和DB2等数据库。
- TABLE:使用一个数据库表来存储生成的主键。这种策略比较灵活,可以用于任何数据库,但可能会影响性能。
- NONE:不使用任何主键生成策略。主键必须由应用程序提供。这种策略适用于不需要自动生成主键的情况。
总之,GenerationType是Hibernate中用于指定实体对象主键生成策略的枚举类型,它包括AUTO、IDENTITY、SEQUENCE、TABLE和NONE等选项。在使用这些选项时,需要根据具体的数据库类型和需求选择适当的生成策略。
<id name="id" type="uuid-binary" column="id" length="16">
<generator class="assigned" />
</id>自定义生成策略
以上只是一些常见的主键生成策略,Hibernate 还支持其他一些策略,以及可以通过扩展 org.hibernate.id.IdentifierGenerator 接口来自定义主键生成策略。选择合适的主键生成策略通常取决于数据库类型、性能需求和应用程序的特定需求。
乐观锁
class 标签的 optimistic-lock 属性用于指定那个字段作为版本号,提供乐观锁功能
<class entity-name="inz.contract.datamodel.Account" table="inz_contract_account"
optimistic-lock="version">
<id name="id" type="uuid-binary" column="id" length="16">
<generator class="assigned" />
</id>
<version name="version" type="int" column="version"/>
</class>关联映射
基本映射
[Hibernate]
create table biz_teacher (
id binary(16) not null,
birthday date,
boolean1 bit,
code varchar(255),
createTime datetime(6),
decimal1 decimal(38,2),
double1 float(53),
float1 float(23),
integer1 integer,
long1 bigint,
short1 smallint,
primary key (id)
) engine=InnoDB类型
Hibernate 中的 @Type 注解用于指定映射实体属性时的 Hibernate 类型。Hibernate 提供了多种内置的基本类型,以及对自定义类型的支持。以下是一些常用的 @Type 注解支持的类型:
基本数据类型:
@Type(type = "int")
@Type(type = "long")
@Type(type = "double")
@Type(type = "string")
@Type(type = "date")
@Type(type = "time")
@Type(type = "timestamp")
枚举类型:
@Type(type = "string"),用于映射枚举的名称或字符串值。
@Type(type = "pgsql_enum"),用于 PostgreSQL 数据库中的枚举类型。
自定义类型:
@Type(type = "com.example.CustomType"),用于映射自定义的 Hibernate 用户类型。
集合类型:
@Type(type = "list")
@Type(type = "map")
@Type(type = "set")
JSON 类型:
@Type(type = "json"),用于映射 JSON 数据。
其他类型:
@Type(type = "binary"),用于映射二进制数据。
@Type(type = "blob"),用于映射大二进制对象。请注意,具体支持的类型可能取决于 Hibernate 的版本和底层数据库的类型。在使用 @Type 注解时,你可以根据具体的需要选择适当的类型。如果你使用的是自定义类型,你可能需要提供自定义的 Hibernate 用户类型实现
枚举
在 Hibernate 中,可以直接映射 Java 枚举类型到数据库表的字段。使用 @Enumerated 注解来指定枚举类型的映射方式。以下是一个简单的例子:
@Entity
@Table(name = "example_entity")
public class ExampleEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "status")
@Enumerated(EnumType.STRING) // 指定映射方式为枚举的字符串表示
private StatusEnum status;
// 其他属性和方法
public enum StatusEnum {
ACTIVE,
INACTIVE,
PENDING
}
}在这个例子中,ExampleEntity 类中的 status 字段是一个枚举类型 StatusEnum。通过使用 @Enumerated 注解,你可以指定枚举类型的映射方式,这里使用的是 EnumType.STRING,表示将枚举映射为字符串。
你还可以使用 EnumType.ORDINAL,表示将枚举映射为整数值。但要注意,EnumType.ORDINAL 映射方式对枚举值的顺序敏感,当枚举值的顺序发生变化时,可能导致数据库中的数据与代码中的枚举值不一致。
在数据库中,status 字段将会被映射为字符串类型(或整数类型,取决于 EnumType 的设置),存储枚举的名称或整数值。
取消映射
在 Hibernate 中,如果你想取消映射实体类的某个字段,你可以使用 @Transient 注解。@Transient 注解用于标识某个字段不需要映射到数据库表,即数据库表中不会存在该字段的列。
public class ExampleEntity {
@Transient
private String transientField; // 使用 @Transient 注解取消映射
// 其他属性和方法
}在关系型数据库中,多表之间存在着三种关联关系,分别为一对一、一对多和多对多。
关联关系描述的是数据库表之间的引用关系,而 Hibernate 关联映射指的就是与数据库表对应的实体类之间的引用关系。
集合映射
Hibernate为集合映射提供了专用的标签元素:
- Set集合映射,就使用
<set>标签表示,无序不可重复 - List集合映射,就使用
<list>标签表示,有序可重复; - Bag映射:它是List与Set集合的结合,使用
<bag>标签表示,无序可重复; - Map集合映射,就使用
<map>标签表示
一对多
在三种关联关系中,一对多(或者多对一)是最常见的一种关联关系。
在关系型数据库中,一对多映射关系通常是由“多”的一方指向“一”的一方。在表示“多”的一方的数据表中增加一个外键,指向“一”的一方的数据表的主键,“一”的一方称为主表,而“多”的一方称为从表。
示例:
- student 表为学生表,id 为学生表的主键,name 表示学生名称;
- grade 表为班级表,id 为班级表的主键,name 表示班级名称;
- gid 为学生表的外键,指向班级表的主键 id;
假设有两个实体类:Department和Employee,一个部门可以有多个员工,而一个员工只能属于一个部门。
Department 实体类
@Entity
@Table(name = "departments")
public class Department {
@Id
@GeneratedValue(generator = "uuid2")
@Column(name = "id", nullable = false,length = 16)
private UUID id;
@Version
private int version;
@Column(name = "department_name")
private String name;
@OneToMany(mappedBy = "department", cascade = CascadeType.REMOVE)
private List<Employee> employees;
// getters and setters
}Employee 实体类
@Entity
@Table(name = "employees")
public class Employee {
@Id
@GeneratedValue(generator = "uuid2")
@Column(name = "id", nullable = false,length = 16)
private UUID id;
@Column(name = "employee_name")
private String name;
@ManyToOne
@JoinColumn(name = "department_id")
private Department department;
// getters and setters
} 在上述示例中,Department类使用了@OneToMany注解表示与Employee类之间是一对多的关系,而Employee类使用了@ManyToOne和@JoinColumn注解表示与Department类之间是多对一的关系。
注意,在一对多关系中,如果不设置 mappedBy 属性和 @JoinColumn 注解,会产生一张额外的数据表 departments_employees 。所以一般情况下都会设置。在多的一方设置@JoinColumn 注解表明在本表中设置一个关联外键,关联 department 表。
只有在双向关联时,才会使用 OneToMany 中的mappedBy这个属性。它指定了在双向关联中,哪个类负责维护关系,上述示例中。
使用 Hibernate 映射“一对多”关联关系时,需要如下步骤:
- 在“多”的一方的实体类中,引入“一”的一方实体类对象作为其属性,并在映射文件中通过
<many-to-one>标签进行映射; - 在“一”的一方的实体类中,以 Set 集合的形式引入“多”的一方实体类对象作为其属性,并在映射文件中通过
<set>标签进行映射。
多对多
控制转移 Inverse
在前面介绍“一对多”还是“多对多”关联关系时,我们都采用是双向关联,即关联的双方都对关联关系进行了维护,例如在学生和班级这种一对多关联中,既描述了学生与班级的关系,又描述了班级与学生的关系。这种双向关联的方式可以让 Hibernate 同时控制双方的关系,但在程序运行时,却很容易产生多余的 SQL 语句,造成重复操作的问题。此时,我们可以使用 Hibernate 提供的反转(inverse)功能,来解决此问题。
在映射文件的 <set> 标签中,有一个 inverse(反转)属性,它的作用是控制关联的双方由哪一方管理关联关系。inverse 属性的取值是 boolean 类型的,当 inverse 属性取值为 false(默认值)时,表示由当前这一方管理双方的关联关系,如果双方 inverse 属性都为 false,双方将同时管理关联关系;取值为 true 时,表示当前一方放弃控制权,由对方管理双方的关联关系。
在一对多关联关系中,通常我们会将“一”的一方的 inverse 属性取值为 true,即由“多”的一方来维护关联关系;而在多对多关联关系中,则任意设置一方的 inverse 属性为 true 即可。
由于学生和班级之间的关联关系是一对多,而学生和课程之间的关联关系是多对多,因此我们可以将这两种关联关系的控制权都交给学生(Student)。下面我们就通过一个实例来演示反转功能。
<hibernate-mapping>
<class name="net.biancheng.www.po.Grade" table="grade" schema="bianchengbang_jdbc">
<id name="id" column="id" type="java.lang.Integer">
<generator class="native"></generator>
</id>
<property name="name" column="name" length="100" type="java.lang.String"/>
<!--设置 inverse 属性为 true,使其丧失对关联关系的控制权,由 Student 来管理关联关系-->
<set name="students" inverse="true">
<key column="gid"></key>
<-many class="net.biancheng.www.po.Student"></one-to-many>
</set>
</class>
</hibernate-mapping>Inverse属性:表示控制权是否转移
- true:控制权已转移【当前一方没有控制权,让对方维护关系】
- false:控制权没有转移【当前一方有控制权】
通过Hibernate Inverse的设置来决定是由谁来维护表和表之间的关系
Inverse是Hibernate双向关系中的基本概念
<class entity-name="com.beecode.inz.contract.datamodel.ContractAsset" table="inz_contract_contract_asset" >
<id name="id" type="uuid-binary" column="id" length="16">
<generator class="assigned" />
</id>
<property name="remark" type="text" not-null="false">
<column name="remark"></column>
</property>
<bag name="details" lazy="true" fetch="select" inverse="true">
<key column="master_id" not-null="true" />
<one-to-many entity-name="com.beecode.inz.contract.datamodel.ContractAssetDetail" />
</bag>
</class>级联操作 cascade
在Hibernate中,级联操作(cascade)是一种用于处理实体关系的方法。它可以应用于实体类的属性上,以指定当父实体发生变化时,子实体应该如何响应。常见的级联操作有:保存、更新、删除和刷新。
整体上来说级联操作并不常用,尤其是 DELETE 等操作非常危险。
级联操作在 CascadeType 枚举中定义了全部类型
public enum CascadeType {
ALL,
PERSIST,
MERGE,
REMOVE,
REFRESH,
DELETE,
SAVE_UPDATE,
REPLICATE,
LOCK,
DETACH;
}实体类中定义级联操作:
@Entity
public class Parent {
@Id
private Long id;
@OneToMany(mappedBy = "parent", cascade = CascadeType.SAVE_UPDATE)
private List<Child> children;
}在这个例子中,我们为Parent实体定义了一个保存级联操作。这意味着当一个Parent实体被保存时,其关联的Child实体也会被自动保存。
关联查询方式
fetch 和 lazy 配置用于数据的查询
lazy 参数值常见有 false 和 true,默认lazy = true ;
fetch 指定了关联对象抓取的方式,参数值常见是select 和 join,默认是select, select方式先查询主对象,再根据关联外键,每一个对象发一个select 查询,获取关联的对象,形成了n+1次查询;而join方式,是left outer join查询,主对象和关联对象用一句外键关联的sql同时查询出来,不会形成多次查询。
<class entity-name="com.beecode.inz.contract.datamodel.ContractAsset" table="inz_contract_contract_asset" >
<property name="remark" type="text" not-null="false">
<column name="remark"></column>
</property>
<bag name="details" lazy="true" fetch="select" inverse="true">
<key column="master_id" not-null="true" />
<one-to-many entity-name="com.beecode.inz.contract.datamodel.ContractAssetDetail" />
</bag>
</class>在映射文件中,不同的组合会使用不同的查询:
1、lazy=”true” fetch = “select”,使用延迟策略,开始只查询出主对象,关联对象不会查询,只有当用到的时候才会发出sql语句去查询 ;
2、lazy=”false” fetch = “select” ,没有用延迟策略,同时查询出主对象和关联对象,产生1+n条sql.
3、lazy=”true”或”false” fetch =“join”,延迟都不会作用,因为采用的是外连接查询,同时把主对象和关联对象都查询出来了.
嵌套类型
在前面的领域建模中,我们使用到了值类型中的嵌套类型。嵌套类型一般是对几个实体类都公用的属性进行包装方便复用,或者是几个属性属于同一个概念把它们放到一个类里面使得语义清晰。
缓存
Hibernate 的缓存分为两类:
一级缓存:
Hibernate内置的,不可卸除;
缓存范围:缓存只能被当前Session对象访问,不能别其他Session对象访问;缓存的生命周期依赖于Session的生命周期;
二级缓存:
使用第三方插件,可插拔;
缓存范围:缓存可以被所有Session共享;缓存的生命周期依赖于应用的生命周期;
一级缓存
Hibernate 一级缓存具有以下特点:
- 一级缓存是 Hibernate 自带的,默认是开启状态,无法卸载。
- Hibernate 一级缓存的生命周期与 Session 保持一致,且一级缓存是 Session 独享的,每个 Session 不能访问其他的 Session 的缓存区,Session 一旦关闭或销毁,一级缓存中的所有对象将全部丢失。
- Hibernate 一级缓存中只能保存持久态对象。当通过 Session 接口提供的 save()、update()、saveOrUpdate() 和 lock() 等方法,对对象进行持久化操作时,该对象会被添加到一级缓存中。
- 当通过 Session 接口提供的 get()、load() 方法,以及 Query 接口提供的 getResultList、list() 和 iterator() 方法,查询某个对象时,会首先判断缓存中是否存在该对象,如果存在,则直接取出来使用,而不再查询数据库;反之,则去数据库查询数据,并将查询结果添加到缓存中。
- 当调用 Session 的 close() 方法时,Session 缓存会被清空。
- 一级缓存中的持久化对象具有自动更新数据库能力。
- 一级缓存是由 Hibernate 维护的,用户不能随意操作缓存内容,但用户可以通过 Hibernate 提供的方法,来管理一级缓存中的内容,如下表。
| 返回值类型 | 方法 | 描述 |
|---|---|---|
| void | clear() | 该方法用于清空一级缓存中的所有对象。 |
| void | evict(Object var1) | 该方法用于清除一级缓存中某一个对象。 |
| void | flush() throws HibernateException | 该方法用于刷出缓存,使数据库与一级缓存中的数据保持一致。 |
刷出缓存
默认情况下,Session 会在以下时间点刷出缓存:
- 当应用程序调用 Transaction 的 commit() 方法时, 该方法先刷出缓存(session.flush()),然后再向数据库提交事务(tx.commit());
- 当应用程序执行一些查询操作时,如果缓存中持久化对象的属性已经发生了变化,会先刷出缓存,以保证查询结果能够反映持久化对象的最新状态;
- 手动调用 Session 的 flush() 方法。
二级缓存
配置开启二级缓存:
在主配置文件中hibernate.cfg.xml :
<!-- 使用二级缓存 -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!--设置缓存的类型,设置缓存的提供商-->
<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property>注:或者在springboot的application.yml 中配置。
高级应用
自定义tuplizer实现
<class entity-name="com.beecode.inz.contract.datamodel.ContractAssetDetail" table="inz_contract_contract_asset_detail" >
<tuplizer entity-mode="dynamic-map" class="com.beecode.bcp.store.hibernate.KObjectEntityTuplizer"/>
<id name="id" type="uuid-binary" column="id" length="16">
<generator class="uuid2" />
</id>
</class>两种实体模式
在Hibernate中,EntityMode是一个枚举类型,用于设置hibernate默认情况下实体对象的类型。它主要有以下两种可选值:
- POJO(Plain Old Java Object):这是最常用的模式,它需要开发者编写持久化类,每个类对应数据库中的一张表。这些类包含了与数据库表对应的属性和字段,以及Hibernate注解来描述对象与表之间的映射关系。
- MAP(Map):这种模式允许开发者在运行期使用Map的Map来进行实体的表示,而不需要编写特定的持久化类。在这种模式下,开发者只需要编写映射文件来描述对象与数据库表之间的映射关系。这种方法适用于动态模型,可以在运行时灵活地处理实体对象 。
总的来说,POJO模式更适合于静态、稳定的数据模型,而MAP模式则更适用于动态、灵活的数据模型。选择哪种模式取决于项目的需求和开发风格。
public enum EntityMode{
/** pojo 实体模式:一个由实体类组成的实体模型 */
POJO( "pojo" ),
/** 动态映射实体模式 :使用java.util.Map定义实体模型 */
MAP( "dynamic-map" );
}Hibernate 内置的两个Tuplizer,分别支持两种实体模式
- PojoEntityTuplizer
- DynamicMapEntityTuplizer
POJO模式
MAP 模式
动态MAP模式下,只需要写映射文件不需要写实体类:
<?xml version="1.0" encoding="UTF-8"?>
<hibernate-mapping xmlns="http://www.hibernate.org/xsd/hibernate-mapping"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.hibernate.org/xsd/hibernate-mapping
http://www.hibernate.org/xsd/hibernate-mapping/hibernate-mapping-4.0.xsd">
<class entity-name="com.beecode.inz.caard.AssetTest" table="asset_test" optimistic-lock="version">
<tuplizer entity-mode="dynamic-map" class="org.hibernate.tuple.entity.DynamicMapEntityTuplizer"/>
<id name="id" type="long"/>
<version name="recver" type="long"/>
<property name="name" type="string" column="name" length="60" not-null="false" unique="true"/>
</class>
</hibernate-mapping>查询:
Object o = hibernateTemplate.get("com.beecode.inz.caard.AssetTest", 1L);
// 创建一个动态的 Map 作为实体
Map<String, Object> userMap = new HashMap<>();
userMap.put("username", "john_doe");
userMap.put("email", "john@example.com");
session.save("User", userMap);自定义Tuplizer
在Hibernate中,AbstractEntityTuplizer是PojoEntityTuplizer的一个抽象类,用于实现将实体对象转换为元组(Tuple)或从元组中还原出实体对象。它提供了一些通用的实体对象到元组的转换逻辑,可以帮助您更容易地实现自定义的Tuplizer。
要使用AbstractEntityTuplizer,您需要继承它并实现一些抽象方法。以下是一个示例:
public class CustomEntityTuplizer extends AbstractEntityTuplizer {
public CustomEntityTuplizer(EntityMetamodel entityMetamodel, PersistentClass mappedEntity) {
super(entityMetamodel, mappedEntity);
}
@Override
protected Getter buildPropertyGetter(Property mappedProperty, PersistentClass mappedEntity) {
// custom logic to build Getter
return super.buildPropertyGetter(mappedProperty, mappedEntity);
}
@Override
protected Setter buildPropertySetter(Property mappedProperty, PersistentClass mappedEntity) {
// custom logic to build Setter
return super.buildPropertySetter(mappedProperty, mappedEntity);
}
@Override
public Object[] getPropertyValues(Object entity) {
// custom logic to convert entity to tuple
return super.getPropertyValues(entity);
}
@Override
public void setPropertyValues(Object entity, Object[] values) {
// custom logic to convert tuple to entity
super.setPropertyValues(entity, values);
}
} 在上面的代码中,我们定义了一个CustomEntityTuplizer类,继承自AbstractEntityTuplizer,并实现了buildPropertyGetter和buildPropertySetter抽象方法,用于构建Getter和Setter,以及getPropertyValues和setPropertyValues方法,用于自定义实体对象到元组的转换逻辑。
然后,我们需要将自定义的Tuplizer配置到实体类的元数据中。以下是一个示例:
@Entity
@Tuplizer(impl = CustomEntityTuplizer.class)
public class Person {
// entity properties
}在上面的代码中,我们使用@Entity注解定义了一个实体类,并使用@Tuplizer注解指定了CustomEntityTuplizer类作为元数据中的Tuplizer实现。
需要注意的是,AbstractEntityTuplizer是一个抽象类,您需要实现其中的抽象方法才能使用它。如果您只是进行普通的查询或持久化操作,可以使用PojoEntityTuplizer,它已经实现了大部分的实体对象到元组的转换逻辑。
AbstractEntityTuplizer
DynamicMapEntityTuplizer
PojoEntityTuplizer
KObjectEntityTuplizer继承 AbstractEntityTuplizer 抽象类,实现抽象方法,依次提供:
public class KObjectEntityTuplizer extends AbstractEntityTuplizer {
public KObjectEntityTuplizer(EntityMetamodel entityMetamodel, PersistentClass mappedEntity) {
super(entityMetamodel, mappedEntity);
}
@Override
public EntityMode getEntityMode() { //设置实体模式
return EntityMode.MAP;
}
@Override
public Class<?> getConcreteProxyClass() { //具体代理类
return KObject.class;
}
@Override
public EntityNameResolver[] getEntityNameResolvers() { //实体名称解析器
return new EntityNameResolver[] { KObjectEntityNameResolver.INSTANCE };
}
@Override
public Class<?> getMappedClass() { //返回由此 tuplizer 管理的 pojo 类
return KObject.class;
}
//构建属性Getter方法
@Override
protected Getter buildPropertyGetter(Property mappedProperty, PersistentClass mappedEntity) {
return new KObjectAttributeGetter(getEntityMetamodel().getSessionFactory(), getType(), mappedProperty);
}
//构建属性Setter方法
@Override
protected Setter buildPropertySetter(Property mappedProperty, PersistentClass mappedEntity) {
return new KObjectAttributeSetter(getType(), mappedProperty);
}
//构建提供实例化对象的方法
@Override
protected Instantiator buildInstantiator(EntityMetamodel entityMetamodel, PersistentClass mappingInfo) {
return new KObjectInstantiator(mappingInfo, getType());
}
//构建代理工厂
@Override
protected ProxyFactory buildProxyFactory(PersistentClass mappingInfo, Getter idGetter, Setter idSetter) {
ProxyFactory pf = new KObjectProxyFactory(getType());
try {
pf.postInstantiate(getEntityName(), null, null, null, null, null);
} catch (HibernateException e) {
logger.error("Unable to create ProxyFactory", e);
pf = null;
}
return pf;
}
//...
}方言
ASTQueryTranslatorFactory 的原理是将 Hibernate 查询语言(HQL)转换成 SQL 查询语句。它的实现主要分为以下几个步骤:
通过 HQLParser 解析 HQL 语句,生成一颗抽象语法树(AST)。
根据语法树的节点类型,使用 ASTFactory 创建对应类型的节点对象,节点对象用于存储对应的语法信息。
将语法树转换成 SQLQuery 对象,SQLQuery 对象表示一个 SQL 查询语句。
使用 ASTWalker 遍历 SQLQuery 对象,根据节点类型生成相应的 SQL 片段。
通过 Dialect 对象,将 SQL 片段拼接成最终的 SQL 查询语句。
最终返回 SQL 查询语句。
ASTQueryTranslatorFactory 通过使用不同的 Dialect,可以支持不同的数据库方言,使得 Hibernate 可以在不同的数据库上运行。它是 Hibernate 内部的一个重要组件,可以将开发者编写的 HQL 语句转换成最终的 SQL 查询语句,从而实现 Hibernate 的查询功能。
属性转换器
场景:
开发中有一个问题,有一个业务对象,它的属性是一个JSONObject对象,但是我们希望存入数据库时,存为json字符串。前端在插入和查询时,都是以对象来处理,所以希望能自动转换,即在插入数据库时,转为字符串,查询出来后转为对象。这就用到了今天要说的属性转换器。
第一步:定义一个属性转换器
public class JSONArrayToStringConverter implements AttributeConverter<JSONArray,String> {
@Override
public String convertToDatabaseColumn(JSONArray object) {
return object==null?null:object.toJSONString();
}
@Override
public JSONArray convertToEntityAttribute(String s) {
return s==null?null: JSONArray.parseArray(s);
}
}这个转换器,实现了javax.persistence.AttributeConverter接口,在存入数据库时,将对象转为字符串,在查询获时,转为实体对象。
第二步:在实体类中标注@Convert注解,并指明转换类。
@Entity
@Table(name = "t_business_rules")
public class BusinessRules extends BaseEntity {
//其他属性...
@Convert(converter = JSONObjectToStringConverter.class)
private JSONObject frequency;
}UserType
Criteria API
HQL和JPQL都是非类型安全的方式来执行查询操作。Criteria 查询提供了一种查询类型安全的方法。
你可以根据需求使用不同的条件接口进行组合,从而构建复杂的查询条件。
@Autowired
private HibernateOperations template;
public List<SubsidyDetail> queryByContractCode(String contractCode) {
Assert.notNull(contractCode,"param contractCode must not be null!");
return template.execute(session -> {
//JPA 分离条件接口
CriteriaBuilder criteriaBuilder = session.getCriteriaBuilder();
CriteriaQuery<SubsidyDetail> criteriaQuery = criteriaBuilder.createQuery(SubsidyDetail.class);
Root<SubsidyDetail> root = criteriaQuery.from(SubsidyDetail.class);
Predicate condition = criteriaBuilder.equal(root.get("contractCode"), contractCode);
criteriaQuery.where(condition);
List<SubsidyDetail> resultList = session.createQuery(criteriaQuery).getResultList();
//执行HQL
String hql = "from " + SubsidyConst.SUBSIDY_DETAIL_ENTITY + " where contractCode=:contractCode";
Query<SubsidyDetail> query = session.createQuery(hql, SubsidyDetail.class);
query.setParameter("contractCode",contractCode);
return query.getResultList();
});
}参考:
https://www.jarcheng.top/blog/knowledge/jpa/hibernate/criteria.html
HibernateProxy
HibernateProxy是Hibernate框架中的一个类,它是一个代理对象,用于延迟加载一个实体类的关联属性。
在Hibernate中,当实体类关联的数据较多时,为了避免一次性查询所有的数据导致性能问题,可以使用延迟加载的方式,即在需要使用关联属性时才去加载,而不是在查询实体类时就加载所有的关联属性。HibernateProxy就是用于实现这种延迟加载的代理对象。
使用HibernateProxy的方式是,当查询到一个实体类时,如果该实体类有延迟加载的关联属性,则该关联属性会被代理成一个HibernateProxy对象。当需要使用该关联属性时,调用HibernateProxy的getTarget()方法就会触发实际的加载过程。
下面是一个示例:
// 查询一个User实体,该实体有一个延迟加载的Order集合属性
User user = session.get(User.class, 1L);
// 调用Order集合属性的方法时,会触发实际的加载过程
Set<Order> orders = user.getOrders();在上述代码中,当调用user.getOrders()方法时,由于Order集合属性是延迟加载的,因此会返回一个HibernateProxy代理对象。当需要使用Order集合属性时,如遍历集合或者调用集合的其他方法时,就会触发实际的加载过程,从数据库中加载相关的数据。
多租户
SaaS(Software as a Service)多租户是指一种软件架构模式,即一个软件系统可以为多个租户提供服务,每个租户都有自己的独立数据和配置,但是这些租户共享同一个应用程序实例。SaaS多租户的目的是为了在一个系统中同时服务多个客户或用户,并且保持每个客户之间的数据和配置的隔离性,以保证数据的安全性和隐私性。
在SaaS多租户架构中,每个租户都有自己的数据和配置,它们被存储在不同的数据库或数据库模式中,每个租户只能访问自己的数据和配置。同时,每个租户都共享同一个应用程序实例,这意味着系统只需要一次部署和维护,可以为多个租户提供服务,并且每个租户都可以享受到系统的最新功能和更新。
SaaS多租户的目的是为了提高软件系统的灵活性、可扩展性和可维护性,同时也可以降低系统的成本和复杂性。对于SaaS供应商而言,SaaS多租户架构可以帮助他们更好地管理客户和数据,减少系统的维护和管理成本,提高系统的可靠性和安全性。对于SaaS客户而言,SaaS多租户架构可以提供更灵活、更定制化的服务,同时也可以保证数据的安全性和隐私性,让客户更加放心地使用SaaS服务。
实现方案
目前有三种多租户实现策略:
- 独立数据库实例 Database (隔离性最强)
- 独立数据库 Schema(共享数据库实例)
- 共享数据库Schema,共享数据表,通过使用标识符列实现多租户。(隔离性最弱)
应该根据实际需求选择合适的多租户策略。
实现原理
Hibernate 是一个广泛使用的 ORM(对象关系映射)框架,支持多租户(Multi-Tenancy)应用程序的开发。
Hibernate 支持上面三种多租户数据隔离策略。

实现步骤
主要分为五步骤:
- 定义Web请求拦截器,获取请求中的tenant-id,存放在context中;
- 实现 CurrentTenantIdentifierResolver 接口,定义当前租户ID解析器;
- 实现 MultiTenantConnectionProvider 接口,定义多租户连接提供器;
- 定义多数据源,提供根据租户ID返回相应的数据源的能力;
- 定义JPA/Hibernate 配置信息
SpringData JPA
Spring Data JPA 是Spring提供的一套简化JPA开发的框架,按照约定好的【方法命名规则】写dao层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。
Spring Data JPA 可以理解为 JPA 规范的再次封装抽象,底层还是使用了 Hibernate 的 JPA 技术实现。
在SpringBoot项目中添加依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>自定义Repository编写
编写实体类:
@Entity
@Table(name = "student")
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String name;
@Column
private Integer age;
//getter setter...
}编写Repository 接口:
/**
* 演示了2种自定义接口的策略:
*
* 1. 基于SpringData JPA的命名规范,直接定义接口
* 2. 使用自定义的SQL语句进行个性化定制,这种适用于一些需要高度定制化处理的场景
*/
@Repository
public interface StudentRepository extends JpaRepository<Student, Long> {
List<Student> findAllByName(String name);
@Query(value = "select * from student where name like %?1%", nativeQuery = true)
List<Student> fuzzyQueryByName(String name);
@Query(value = "from com.example.jpa.entity.Student", nativeQuery = false)
List<Student> fuzzyQueryByName2();
} Spring Data repository 抽象的中心接口是 Repository。它把要管理的 domain 类以及 domain 类的ID类型作为泛型参数。这个接口主要是作为一个标记接口,用来捕捉工作中的类型,并帮助你发现扩展这个接口的接口。 CrudRepository 和 ListCrudRepository 接口为被管理的实体类提供复杂的CRUD功能。
查询操作
原生SQL查询
@Query(value = "select * from Book b where b.name=?1", nativeQuery = true)
List<Book> findByName(String name);
@Query(value = "select name,price from Book b where b.name = :name AND b.author=:author")
List<Book> findByNamedParam(@Param("name") String name, @Param("author") String author);模糊查询
范围查询
分页查询
Page<User> findALL(Pageable pageable);
Page<User> findByUserName(String userName,Pageable pageable); 多表+动态查询
创建结果实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class UserArticleDTO {
private Integer id;
private String name;
private String articleName;
}编写Repository
@Repository
public class UserArticleDao {
@Autowired
@PersistenceContext
private EntityManager em;
static final Integer PAGE_SIZE = 2;
public List<UserArticleDTO> findUserArticle(int currentPage) {
CriteriaBuilder builder = em.getCriteriaBuilder();
CriteriaQuery<UserArticleDTO> query = builder.createQuery(UserArticleDTO.class);
// from table
Root<User> rootUser = query.from(User.class);
Root<Article> rootArticle = query.from(Article.class);
// where conditions
List<Predicate> predicates = new ArrayList<>();
Predicate predicate1 = builder.equal(rootUser.get("id"), rootArticle.get("userId"));
Predicate predicate2 = builder.equal(rootArticle.get("articleName"), "macbook");
Predicate predicate3 = builder.like(rootArticle.get("articleName"), "%ms surface%");
Predicate predicateOr = builder.or(predicate2, predicate3);
predicates.add(predicate1);
predicates.add(predicateOr);
Predicate finalPredicate = builder.and(predicates.toArray(new Predicate[predicates.size()]));
query.multiselect(rootUser.get("id").as(Integer.class), rootUser.get("name").as(String.class),
rootArticle.get("articleName").as(String.class))
.where(finalPredicate);
// no paging
// List<UserArticleDTO> resultList = em.createQuery(query).getResultList();
// add paging to query
TypedQuery<UserArticleDTO> typedQuery = em.createQuery(query);
typedQuery.setFirstResult((currentPage - 1) * PAGE_SIZE);
typedQuery.setMaxResults(PAGE_SIZE);
// execute query
List<UserArticleDTO> resultList = typedQuery.getResultList();
return resultList;
}
}测试
@Test
public void testUserArticleDao() {
List<UserArticleDTO> userArticle = userArticleDao.findUserArticle(1);
for (UserArticleDTO userArticleDTO : userArticle) {
System.out.println(userArticleDTO);
}
}变更操作
update或delete时必须使用@Modifying和@Transactional对方法进行注解
JPA 注解
| 注解 | 描述 |
|---|---|
| @Entity | |
| @Table | |
| @Id |
方法命名约定
Repository方法命名约定
| Keyword | Sample | JPQL snippet |
|---|---|---|
And |
findByLastnameAndFirstname |
… where x.lastname = ?1 and x.firstname = ?2 |
Or |
findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
Is, Equals |
findByFirstname,findByFirstnameIs,findByFirstnameEquals |
… where x.firstname = ?1 |
Between |
findByStartDateBetween |
… where x.startDate between ?1 and ?2 |
LessThan |
findByAgeLessThan |
… where x.age < ?1 |
LessThanEqual |
findByAgeLessThanEqual |
… where x.age <= ?1 |
GreaterThan |
findByAgeGreaterThan |
… where x.age > ?1 |
GreaterThanEqual |
findByAgeGreaterThanEqual |
… where x.age >= ?1 |
After |
findByStartDateAfter |
… where x.startDate > ?1 |
Before |
findByStartDateBefore |
… where x.startDate < ?1 |
IsNull, Null |
findByAge(Is)Null |
… where x.age is null |
IsNotNull, NotNull |
findByAge(Is)NotNull |
… where x.age not null |
Like |
findByFirstnameLike |
… where x.firstname like ?1 |
NotLike |
findByFirstnameNotLike |
… where x.firstname not like ?1 |
StartingWith |
findByFirstnameStartingWith |
… where x.firstname like ?1 (parameter bound with appended %) |
EndingWith |
findByFirstnameEndingWith |
… where x.firstname like ?1 (parameter bound with prepended %) |
Containing |
findByFirstnameContaining |
… where x.firstname like ?1 (parameter bound wrapped in %) |
OrderBy |
findByAgeOrderByLastnameDesc |
… where x.age = ?1 order by x.lastname desc |
Not |
findByLastnameNot |
… where x.lastname <> ?1 |
In |
findByAgeIn(Collection<Age> ages) |
… where x.age in ?1 |
NotIn |
findByAgeNotIn(Collection<Age> ages) |
… where x.age not in ?1 |
True |
findByActiveTrue() |
… where x.active = true |
False |
findByActiveFalse() |
… where x.active = false |
IgnoreCase |
findByFirstnameIgnoreCase |
… where UPPER(x.firstame) = UPPER(?1) |
自动Audit
代码里面其实并没有对create_time和update_time字段进行赋值,但是数据存储到DB的时候,这两个字段被自动赋值了,这个主要是因为开启了自动Audit能力,主要2个地方的代码有关系:
1、Application启动类上的注解,开启允许JPA自动Audit能力
@EnableJpaAuditing
2、Entity类上添加注解
@EntityListeners(value = AuditingEntityListener.class)
3、Entity中具体字段上加上对应注解:
@CreatedDate
private Date createTime;
@LastModifiedDate
private Date updateTime;重要配置
在Spring Boot中,可以使用以下属性来配置EntityManagerFactoryBean:
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect其中,spring.jpa.hibernate.ddl-auto属性指定Hibernate在启动时如何更新数据库模式。可以设置为create(每次启动时重新创建数据库表)、update(每次启动时更新表结构)或none(不更新表结构)。
spring.jpa.show-sql属性指定是否在控制台上打印SQL语句。
spring.jpa.properties.hibernate.dialect属性指定使用的Hibernate方言。根据数据库类型的不同,需要使用不同的方言。以上示例中使用的是MySQL5InnoDBDialect。
EntityManagerFactoryBean
EntityManagerFactoryBean 和 SessionFactoryBean都是用于配置Hibernate的Spring Bean,但它们之间存在一些区别:
- EntityManagerFactoryBean是用于JPA(Java Persistence API)配置的,而SessionFactoryBean是用于Hibernate配置的。虽然两者都可以用来管理Hibernate的Session,但EntityManagerFactoryBean是JPA API的一部分,而SessionFactoryBean是Hibernate API的一部分。
- EntityManagerFactoryBean是基于JPA规范,因此在使用JPA时必须使用该Bean。而SessionFactoryBean只能用于Hibernate,不能用于其他ORM框架。
- EntityManagerFactoryBean是用于管理EntityManagerFactory的Spring Bean,而SessionFactoryBean是用于管理SessionFactory的Spring Bean。EntityManagerFactory是JPA的中心接口,用于创建EntityManager实例,而SessionFactory是Hibernate的中心接口,用于创建Session实例。
- EntityManagerFactoryBean通常与Hibernate的JPA实现一起使用,如Hibernate EntityManager(Hibernate的JPA实现),而SessionFactoryBean则可以与任何Hibernate实现一起使用。
总的来说,EntityManagerFactoryBean 和 SessionFactoryBean都是用于配置Hibernate的Spring Bean,但EntityManagerFactoryBean是用于JPA配置的,而SessionFactoryBean是用于Hibernate配置的。这两个Bean都有各自的用途,具体取决于您的需求和使用情况。
JPA与Mybatis和Hibernate区别
Spring Data JPA 使用Hibernate来实现的,但使用方式上与Hibernate有很多区别。
首先Spring JPA 不需要编写映射文件。
基本的增删改查操作接口已经提供,
多参数查询可以在遵循方法命名规范的情况下,无需编写SQL,提高开发效率;
Hibernate Data Repositories
Jakarta Data 是存储库的新规范。在此上下文中,存储库是指公开类型安全 API 以与数据存储交互的接口。Jakarta Data 旨在适应各种数据库技术,从关系数据库到文档数据库,再到键值存储等等。
Hibernate Data Repositories 是 Jakarta Data 的一个实现,针对关系数据库,并由 Hibernate ORM 支持。实体类使用 Jakarta Persistence 定义的熟悉注释进行映射,查询可以用 Hibernate 查询语言编写,它是 Jakarta Persistence 查询语言 (JPQL) 的超集。
在本文中,我将使用 Hibernate ORM 作为我的 Jakarta Data 实现。正如我的入门指南中提到的,您将 Jakarta Data 存储库定义为接口。从 6.6 版开始,Hibernate 的元模型生成器会在编译时创建所需的存储库实现。
生成的代码使用 Hibernate 的专有 StatelessSession。与普通 Session 和 JPA 的 EntityManager 相比,StatelessSession 不管理实体对象的生命周期,不支持隐式延迟获取,也不使用任何缓存。这使得它非常适合实现 Jakarta Data 存储库。
所有生成的存储库实现都可以在项目的 target/generated-sources 文件夹中轻松找到。Hibernate 的元模型生成器将它们存储在与存储库接口相同的包中,并通过在存储库接口的名称后附加“_”来生成它们的名称。
因此,对于我的存储库接口 com.thorben.janssen.repository.ChessPlayerRepository,Hibernate 生成类 com.thorben.janssen.repository.ChessPlayerRepository_ 作为其实现。
引入依赖
<dependency>
<groupId>org.hibernate.orm</groupId>
<artifactId>hibernate-core</artifactId>
</dependency>
<dependency>
<groupId>jakarta.data</groupId>
<artifactId>jakarta.data-api</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate.orm</groupId>
<artifactId>hibernate-jpamodelgen</artifactId>
</dependency>1.定义实体类
2.定义接口
@Repository //jakarta.data.repository 包
public interface TeacherDao {
@Insert
void add(Teacher teacher);
@Update
void update(Teacher teacher);
@Delete
void delete(Teacher teacher);
@Find
Teacher teacher(UUID id);
/**
* 查询列表、排序
* @param code
* @return
*/
@Find
@OrderBy("code")
List<Teacher> bookListOrderBy(String code);
/**
* 排序
* 限制条数
* @param code
* @param limit
* @param order
* @return
*/
@Find
List<Teacher> bookListOrderByLimit(String code, Limit limit, Order<Teacher> order);
/**
* hql 语句查询
* @param code
* @return
*/
@Query("from Teacher where code= :code")
List<Teacher> bookListHql(String code);
/**
* 分页
* @param code
* @param pageRequest
* @return
*/
@Find
Page<Teacher> bookListPage(String code,
PageRequest pageRequest);
}注册为Spring Bean:
@Configuration
public class AutoConfig {
@Autowired
private SessionFactory sessionFactory;
@Bean
public TeacherDao teacherDao(){
//TeacherDao_ 实现类是 HibernateProcessor 在编译时自动生成的类
return new TeacherDao_(sessionFactory.openStatelessSession());
}
}使用
@Service
@Transactional
public class TeacherService {
@Autowired
private SessionFactory sessionFactory;
@Autowired
private TeacherDao teacherDao;
public void addTeacher(Teacher teacher){
teacherDao.add(teacher);
teacher.setBirthday(LocalDate.now());
teacherDao.update(teacher);
List<Teacher> bookListOrderBy = teacherDao.bookListOrderBy("1");
List<Teacher> bookListHql = teacherDao.bookListHql("1");
PageRequest pageRequest = PageRequest.ofPage(2);
Page<Teacher> teachers = teacherDao.bookListPage("1", pageRequest);
List<Teacher> content = teachers.content();
long l = teachers.totalElements();
// teacherDao_.delete(teacher);
}常见问题
原生SQL与HQL混合使用出现的问题
场景:
在一个事务中,有多条更新SQL语句,其中代码中的原生SQL在HQL之前,但执行过程却是HQL先执行,原生SQL后执行,实际执行顺序与代码的编写顺序不一致。
解决方法:
将原生SQL改为HQL方式执行。
查询实体与HQL混合使用出现的问题
场景:
在一个事务中,先查询实体。再使用HQL对该实体进行部分字段的更新。最终执行结果是HQL执行后,又多一条更新该表的SQL出现,导致后面的更新SQL把前面的更新给覆盖掉。相当于没更新。
解决:
方式1:使用session.update(entity) 的方式更新数据,取消HQL方式;
方式2:在HQL执行完之后,理解调用session.refresh(entity) 再次查询数据库,从而更新持久化实体对象。这样事务提交时触发session.flush(),再次更新实体就不会覆盖原先已经更新的数据了。
Hibernate6
AvailableSettings生成的代码使用 Hibernate 专有的 StatelessSession。与普通 Session 和 JPA 的 EntityManager 不同,StatelessSession 不管理实体对象的生命周期,不支持隐式延迟获取,也不使用任何缓存。这使得它非常适合实现 Jakarta 数据存储库。
README
作者:银法王
参考:
Hibernate ORM 用户手册 6.6.0.Final
Hibernate Data Repositories 教程
超凡Code闲聊