KV存储之Redis完全指北
Redis
Redis(Remote Dictionary Server)是一个开源(BSD协议)的高性能 Key-Value 型内存数据库,提供多种语言的客户端API。Redis 也被称为数据结构服务器,它存储的value 可以是字符串、哈希、列表、集合和有序集合等常用的数据类型。
发展历程
| 版本 | 时间线 | 描述 |
|---|---|---|
| Redis 3.0 | 2015年4月 | Redis Cluster: Redis的官方分布式实现 |
| Redis 3.2 | 2016年5月 | 新的List编码类型:quicklist |
| Redis 4.0 | 2017年7月 | 提供了新的缓存剔除算法:LFU |
| Redis 5.0 | 2018年10月 | 新的Stream 数据类型 |
| Redis 6.0 | 2020年4月 | 多线程 IO |
| Redis 7.0 | 2022年4月 |
下载和安装
- 在生产环境或者开发环境,都可以用docker的方法来安装redis。
- 在开发环境中,windows下最简单的办法是安装针对windows平台编译的redis版本,可以在 这里 下载合适的新版本,建议安装6.0以上的版本。
功能特性
- 高性能 (单机读 11W次/s,写8W次/s)
- 高可用 (主从、哨兵、集群)
- 支持多种数据类型(字符串、hash、列表、集合、有序集合)
- 功能丰富:支持数据持久化、事务、发布订阅、Lua脚本等功能
- 单线程工作模式,并发安全;采用IO多路复用机制
- Redis 的所有操作都是原子性的,同时 Redis 还支持对几个操作合并后的原子性执行。
客户端
命令行
Redis 支持客户端使用CLI 命令行的方式与服务器进行交互,所有命令在官网都能查到详细说明,本文只示例几种常用的操作,更全面的命令操作请参考官网。
| 命令 | 描述 |
|---|---|
| DEL key | 删除key,返回删除的条数 |
| EXISTS key | 检查 key 是否存在,存在返回1,不存在返回0 |
| RENAME key newkey | 重命名key |
| RENAMENX key newkey | 仅当 newkey 不存在时, 重命名key |
| TYPE key | 返回key所存储的value 类型 |
| MOVE key db | 将key 移动到其他数据库 |
| TTL key | 查看key的过期时间,单位:秒;-1代表永不过期,-2表示已经过期; |
| EXPIRE key [seconds] | 设置key的过期时间,单位:秒; |
| EXPIREAT key [timestamp] | 设置key的过期时间,同上不同的是设置UNIX 时间戳; |
| PERSIST key | 移除key的过期时间, key永不过期; |
| KEYS [pattern] | 查找符合给定表达式的所有key |
Java 客户端
Redis支持几十种编程语言的客户端操作,如 C、C++、C#、Java、Python、Go、Objective-C 等等;其中支持的Java语言客户端就有多种,下面三个是比较主流的Java客户端程序:
- Jedis
- Lettuce
- Redisson
Jedis
一个比较轻巧的Redis Java客户端,其API提供了比较全面的Redis命令的支持。Jedis中的方法调用是比较底层的暴露的Redis的API,也即Jedis中的Java方法基本和Redis的API保持着一致,了解Redis的API,也就能熟练的使用Jedis。
Lettuce
高级Redis客户端,用于线程安全的同步,异步和反应式使用。 支持集群,哨兵,管道和编解码器。是SpringBoot2 中默认使用的Redis Java客户端。
Redisson
Redisson 是用于构建分布式应用的 Redis Java客户端。Redisson实现了分布式和可扩展的Java数据结构,提供很多分布式相关操作服务,例如,分布式锁,分布式集合,可通过Redis支持延迟队列。
项目地址:https://github.com/redisson/redisson
中文文档:https://github.com/redisson/redisson/wiki/%E7%9B%AE%E5%BD%95
技术选型
Jedis 和 Lettuce 对Redis服务的基本操作提供了比较全面的API支持,Redisson 在这方面不如前两者,但Redisson 提供了很多构建分布式应用的特性,所以在实际项目(java)中,我们推荐 Lettuce 和 Redisson混合使用。
Spring Data 项目提供了 RedisTemplate ,它对Jedis 和 Lettuce 进行封装,在SpringBoot 项目中我们可以引入 spring-boot-starter-data-redis 模块来轻松操作Redis。
数据类型
Redis支持以下几种常用的数据类型:
- String 字符串
- Hash 哈希表
- List 列表
- Set 集合
- SortedSet 有序集合
注:使用
type key命令可以查看key对应的value 是什么数据类型
字符串
字符串 string 是 Redis 最简单、最常用的数据类型。string 是二进制安全的,意思是Redis的String可以包含任何数据,包括 jpg图片或序列化的对象。
二进制安全:
二进制安全是一种主要用于字符串操作函数相关的计算机编程术语。二进制安全的意思就是,只关心字符串对应的二进制化数据,而不关心具体格式,只会严格的按照二进制的数据存取,不会妄图以某种特殊格式解析数据。
基本操作
常用字符串命令:
set key value [ex seconds] [px milliseconds] [nx|xx]: 设置值,返回 ok 表示成功
- ex seconds:为键设置过期时间(单位:秒)。
- px milliseconds:为键设置过期时间(单位:毫秒)。
- nx: 键必须不存在才可以设置成功,用于新增。可单独用 setnx 命令替代
- xx:与nx相反,键必须存在才可以设置成功,用于更新。可单独用 setxx 命令替代
get key:获取值
mset key value [key value …]:批量设置值,批量操作命令可以有效提高处理效率
mget key [key …]:批量获取值,批量操作命令可以有效提高业务处理效率
incr key:自增1,返回结果分 3 种情况:
- 值不是整数,返回错误。
- 值是整数,返回自增后的结果。
- 键不存在,按照值为0自增,返回结果为1。
decr(自减1)、 decrby(自减指定数字)、incr(自增1)、incrby(自增指定数字)
getrange key start end 范围查找子字符串
应用场景
- 缓存,提高查询性能。比如存储登录用户信息、电商中存储商品信息;
- 计数器(比如限制一个IP地址在一定时间内对网站的访问次数),短信限流;
- 共享 Session,例如:一个分布式Web服务将用户的Session信息(例如用户登录信息)保存在各自服务器中,这样会造成一个问题,出于负载均衡的考虑,分布式服务会将用户的访问均衡到不同服务器上,用户刷新一次访问可 能会发现需要重新登录,为了解决这个问题,可以使用Redis将用户的Session进行集中管理,在这种模式下只要保证Redis是高可用和扩展性的,每次用户 更新或者查询登录信息都直接从Redis中集中获取。
哈希表
Redis hash 是一个string 类型的 field-value 映射表,和Java中的HashMap 以及 Js 中的 Map 非常相似,内部是无序字典。hash 非常适合用于存储对象,比如用户信息。
基本操作
常用哈希命令
- hset key field value:设置值
- hsetnx key field value:设置值(只有当哈希表该字段不存在时才能设置成功,防止覆盖)
- hget key field:获取值
- hkeys key:获取所有field
- hvals key:获取所有value
- hgetall key:获取所有的field-value
- hmset key field value [field value …]:批量设置field-value
- hmget key field [field …]:批量获取field-value
- hdel key field [field …]:删除field
- hlen key:计算field个数
- hexists key field:判断field是否存在
- hincrby key field increment 给field增加指定值
应用场景
常用于存储对象及其属性信息:
1、由于hash数据类型的key-value的特性,用来存储关系型数据库中表记录,是redis中哈希类型最常用的场景。一条记录作为一个key-value,把每列属性值对应成field-value存储在哈希表当中,然后通过key值来区分表当中的主键。
2、经常被用来存储用户相关信息。优化用户信息的获取,不需要重复从数据库当中读取,提高系统性能。
列表List
Redis 中的 List 实现原理是一个双向链表,而不是数组,相当于 Java 中的 LinkedList,这意味着 List的插入和删除很快,时间复杂度为O(1),但是索引定位慢,时间复杂度为O(n)。
基本操作
常用列表命令
rpush key value [value …]:从右边插入元素
lpush key value [value …]:从左边插入元素
linsert key before|after pivot value:向某个元素前或者后插入元素
lpop key:从列表左侧弹出元素
rpop key:从列表右侧弹出
lrem key count value:删除指定元素,lrem命令会从列表中找到等于value的元素进行删除,根据count的不同 分为三种情况:
- ·count>0,从左到右,删除最多count个元素。
- count<0,从右到左,删除最多count绝对值个元素。
- count=0,删除所有。
lrange key start end:获取指定范围内的元素列表,
lrange key 0 -1可以从左到右获取列表的所有元素lindex key index:获取列表指定索引下标的元素
llen key:获取列表长度
ltrim key start end:按照索引范围修剪列表
lset key index newValue:修改指定索引下标的元素
blpop key [key …] timeout 和 brpop key [key …] timeout:阻塞式弹出
应用场景
1、消息队列:reids的链表结构,可以轻松实现阻塞队列,可以使用左进右出的命令组成来完成队列的设计。比如:数据的生产者可以通过Lpush命令从左边插入数据,多个数据消费者,可以使用BRpop命令阻塞的“抢”列表尾部的数据。
2、文章列表或者数据分页展示的应用。比如,我们常用的博客网站的文章列表,当用户量越来越多时,而且每一个用户都有自己的文章列表,而且当文章多时,都需要分页展示,这时可以考虑使用redis的列表,列表不但有序同时还支持按照范围内获取元素,可以完美解决分页查询功能。大大提高查询效率。
使用参考:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
集合
Redis的 Set 是String类型的无序集合,集合中的元素是唯一的,不可重复。相当于 Java 语言里面的 HashSet 和 JS 里面的 Set。
基本操作
常用集合命令
- sadd key element [element …]:添加元素,返回结果为添加成功的元素个数
- srem key element [element …]:删除元素,返回结果为成功删除元素个数
- smembers key:获取所有元素
- sismember key element:判断元素是否在集合中,如果给定元素element在集合内返回1,反之返回0
- scard key:计算元素个数,scard的时间复杂度为O(1),它不会遍历集合所有元素
- spop key:从集合随机弹出元素,从3.2版本开始,spop也支持[count]参数。
- srandmember key [count]:随机从集合返回指定个数元素,[count]是可选参数,如果不写默认为1
- sinter key [key …]:求多个集合的交集
- suinon key [key …]:求多个集合的并集
- sdiff key [key …]:求多个集合的差集
应用场景
1、标签:比如我们博客网站常常使用到的兴趣标签,把一个个有着相同爱好,关注类似内容的用户利用一个标签把他们进行归并。
2、共同好友功能,共同喜好,或者可以引申到二度好友之类的扩展应用。
3、统计网站独立IP。利用set集合当中元素不唯一性,可以快速实时统计访问网站的独立IP。
有序集合
Redis中的 Zset 和 Set 类似,区别是Zset 内部元素是有序的,Zset 额外提供一个 score 参数(浮点型)来为成员排序,并且插入是有序的,即自动排序。当你需要一个有序的并且不重复的集合,那么可以选择sorted Set。
Zset 中成员的值是唯一的,但分数(score)却可以重复。
基本操作
常用有序集合命令
zadd key score member [score member …]:添加成员,返回结果代表成功添加成员的个数。
- nx:member必须不存在,才可以设置成功,用于添加
- xx:member必须存在,才可以设置成功,用于更新
- incr:对score做增加,相当于后面介绍的zincrby
zincrby key increment member:增加成员的分数
zcard key:计算成员个数
zscore key member:查看某个成员的分数
zrank key member 和 zrevrank key member:计算成员的排名,zrank是从分数从低到高返回排名,zrevrank反之
zrem key member [member …]:删除成员
zrange key start end [withscores] 和 zrevrange key start end [withscores]:返回指定排名范围的成员,zrange是从低到高返回,zrevrange反之。
zrangebyscore key min max [withscores] [limit offset count] 和 zrevrangebyscore key max min [withscores] [limit offset count] 返回指定分数范围的成员,其中zrangebyscore按照分数从低到高返回,zrevrangebyscore反之
zcount key min max:返回指定分数范围成员个数
注:
有序集合相比集合提供了排序字段,但是也产生了代价,sadd的时间复杂度为O(1),而zadd的时间 复杂度为O(log(n))。
应用场景
- 排行榜:有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:按照时间、按照播放量、按照获得的赞数等。
- 用Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
Key的使用规范
Redis中单个Key的存储上限是512M。命令的关键字不区分大小写,key 的名称是区分大小写的;
- Key 的命名以英文字母开头,建议只使用小写英文字母、数字、英文点号(.)和冒号(:);
- Key 的命名应该具有可读性,不应该含义不清或太短;
- Key 不能过长,尽量不要超过1Kb,过大的key不仅消耗过多内存,而且会降低查找效率;
- 在一个项目中,Key 应该使用统一的命名规范,例如
user:id:10020:name(表名:主键名:主键值:字段名)。
注:keys * 命令在生产环境下谨慎使用,因为Redis是单线程执行指令,所以在大数据量情况下执行会影响性能;
小结
应用场景汇总
| 类型 | 描述 | 特性 | 场景 |
|---|---|---|---|
| String字符串 | 最简单、最常用的数据类型,二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | 1.缓存 2.计数器 3.共享 Session |
| Hash 字典 |
string 类型的 field-value 映射表 | 适合存储对象信息 | 1.通用对象存储 2.购物信息等 |
| List 列表 |
用于存储多个元素的容器 | 底层是一个双向链表,提供从两端分别插入和弹出元素的功能,方便实现栈和队列。 | 1.热销榜,文章列表 2.工作队列 3.最新列表,如最新评论 |
| Set 集合 |
集合内元素不重复且无序 | 为集合提供了求交集、并集、差集等操作 | 1,.给用户添加标签 2.给标签添加用户 3.社交相关(交集,并集,差集) |
| ZSet有序集合 | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经自动进行排序 | 1、排行榜 2、优先队列 |
数据淘汰策略
Redis服务器的内存容量是有限的,不可能只增不删,因此需要淘汰数据。
Redis 有两种数据淘汰策略:
- 为数据key设置过期时间;
- 采用淘汰策略自动淘汰数据;
过期时间
单独设置key过期时间的指令:
# 指定key多少秒后过期
EXPIRE key seconds;
# 指定key多少毫秒后过期
PEXPIRE key milliseconds
# 指定key在时间戳后过期(自1970年1月1日以来的秒数)
EXPIREAT key timestamp
# 指定key在时间戳后过期(自1970年1月1日以来的毫秒数)
PEXPIREAT key timestamp如果设置成功返回 1,如果key不存在返回0 ;
当然你也可以在设置值时同时指定过期时间,并且可以保证设值和设过期时间的原子性。
# 设置值时指定过期时间
SET key value EX 60;设置了有效期后,可以通过 ttl 和 pttl 两个命令来查询剩余过期时间:
# 返回 key 剩余过期秒数
ttl key
# 返回 key 剩余过期毫秒数
pttl key 过期策略
删除一个过期的键,一般有三种策略:
- 定时删除:即每个键设置一个定时器,到期自动删除;(缺点是占用过多的CPU计算资源)
- 惰性删除:每次判断获取键时判断是否过期,如果过期就删除;(缺点是占用过多的内存资源)
- 定期扫描:系统每隔一段时间就定期扫描一次设置过期时间的键,如果过期就删除;(缺点是可能返回已经过期的键)
Redis采用的是 惰性删除 + 定期扫描 的方式淘汰过期的键,也就是策略2和策略3结合使用。Redis只会定期扫描设置过期时间的键,不会扫描所有键。
淘汰策略
通过 maxmemory 命令或配置文件可以设置 Redis 最大使用内存,如果Redis 内存满了,此时继续写入数据,默认情况下,Redis会内存溢出并报错,如果不想内存溢出,可以选择Redis 提供的内存淘汰策略来解决。
Redis 提供以下几种淘汰策略:
- volatile-lru :在已设定过期时间的数据中,删除最近最少使用的数据;
- allkeys-lru : 在所有key中,删除最近最少使用的数据,这是应用最广泛的策略;
- volatile-random :在已设定过期时间的数据中,随机删除;
- allkeys-random :在所有key中,随机删除数据;
- volatile-ttl :在已设定过期时间的数据中,排序然后删除最快过期的数据;
- noeviction :如果设置该属性,则不会进行删除操作,如果内存溢出则报错返回(默认策略);
- volatile-lfu :在已设定超时时间的数据中,删除最少使用的数据;
- allkeys-lfu :在所有key中,删除最少使用的数据;
注:LRU (Least Recently Used最近最少使用算法)和 LFU (最少使用算法)都是页面置换算法,LRU是Redis最早支持的内存淘汰策略,LFU是Redis5.0版本引入的。
Redis的默认策略是
noeviction,即不会淘汰数据,只是在写操作时返回错误。
高级进阶
除了常用数据类型的支持,Redis还支持多种功能特性:
- 事务
- Lua脚本
- 管道
- 发布订阅
- Stream
- Geo地理位置
- HyperLogLog
- 布隆过滤器
事务
许多情况下我们需要一次执行多个命令,而且需要其同时成功或者失败。为了保证多个命令组合的原子性,Redis 提供了简单的事务功能以及集成 Lua 脚本来解决这个问题。
Redis 提供了简单的事务功能,将一组需要一起执行的命令放到 multi 和 exec 两个命令之间。Multi 命令代表事务开始,exec 命令代表事务结束,它们之间的命令是原子顺序执行的(按顺序依次执行,中间不允许执行任何其他命令)。
事务相关命令:
MULTI # 开启事务;
EXEC # 执行事务块内的所有命令
DISCARD # 取消事务块内的所有命令
WATCH # 监视一个/多个key,如果在事务执行之前这个key被修改,那么事务将被打断;
UNWATCH # 取消所有Key的监视;示例:
> multi
OK
> SET msg "hello world"
QUEUED
> GET msg
QUEUED
> EXEC
1) OKRedis事务错误处理分两种情况:
- 加入命令队列的过程中,发生报错(如命令输入错误),则整个命令队列都会被取消,事务结束;
- 执行命令队列时,发生报错,则只是报错的命令不会执行,其他命令正常执行;
Redis 提供了简单的事务,之所以说它简单,主要是因为它不支持事务中的回滚特性,同时无法实现命令之间的逻辑关系计算,主要有以下几点:
- 不够满足原子性。一个事务执行过程中,其他事务或 client 是可以对相应的 key 进行修改的(并发情况下,例如电商常见的超卖问题),想要避免这样的并发性问题就需要使用 WATCH 命令,但是通常来说,必须经过仔细考虑才能决定究竟需要对哪些 key 进行 WATCH 加锁。然而,额外的 WATCH 会增加事务失败的可能,而缺少必要的 WATCH 又会让我们的程序产生竞争条件。
- 后执行的命令无法依赖先执行命令的结果。由于事务中的所有命令都是互相独立的,在遇到 exec 命令之前并没有真正的执行,所以我们无法在事务中的命令中使用前面命令的查询结果。我们唯一可以做的就是通过 watch 保证在我们进行修改时,如果其它事务刚好进行了修改,则我们的修改停止,然后应用层做相应的处理。
- 事务中的每条命令都会与 Redis 服务器进行网络交互。Redis 事务开启之后,每执行一个操作返回的都是 queued,这里就涉及到客户端与服务器端的多次交互,明明是需要一次批量执行的 n 条命令,还需要通过多次网络交互,显然非常浪费(这个就是为什么会有 pipeline 的原因,减少 RTT 的时间)。
针对于Redis 的事务缺陷,可以通过执行 Lua 脚本来解决。
Lua脚本
Lua 是一种轻量小巧的脚本语言,用标准 C 语言编写并以源代码形式开放,其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。Redis 通过内嵌支持 Lua 环境,使用内置的解释器来执行Lua 脚本。
使用 eval 命令执行Lua脚本,eval 语法::
eval script numkeys key [key ...] arg [arg ...]其中:
- script 一段 Lua 脚本或 Lua 脚本文件所在路径及文件名
- numkeys Lua 脚本对应参数数量
- key [key …] Lua 中通过全局变量 KEYS 数组存储的传入参数
- arg [arg …] Lua 中通过全局变量 ARGV 数组存储的传入附加参数
示例:
EVAL ./release.lua 1 my:lock lock:394A23CC43release.lua 脚本:如果指定键的值与入参值相同,则删除该键值。
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end下面是一些常用的Lua 语法示例,更过Lua语法请参考官网:
-- 定义一个局部变量val,并输出
local val = "hello"
print(val)
-- 定义一个数组,输出第一个值,下标从1开始
local myTable = { "redis", "lua", true, 8 }
print(myTable[1])
-- 使用for循环计算0到10的和
local num = 0
for i = 1, 10 do
num = num + i
end
-- 使用while 计算0到10的和
local sum = 0
local i = 0
while i <= 10 do
sum = sum + i
i = i + 1
end
-- 遍历数组,#myTable2 用于取数组的大小。if-then-else-end 判断
local myTable2 = { "python", "redis", "java" }
for i2 = 1, #myTable2 do
if myTable2[i2] == "redis" then
print("true")
break
else
print("false")
end
end
-- 函数定义:函数以function开头,以end结尾
function add(param1, param2)
return param1 + param2
end管道技术
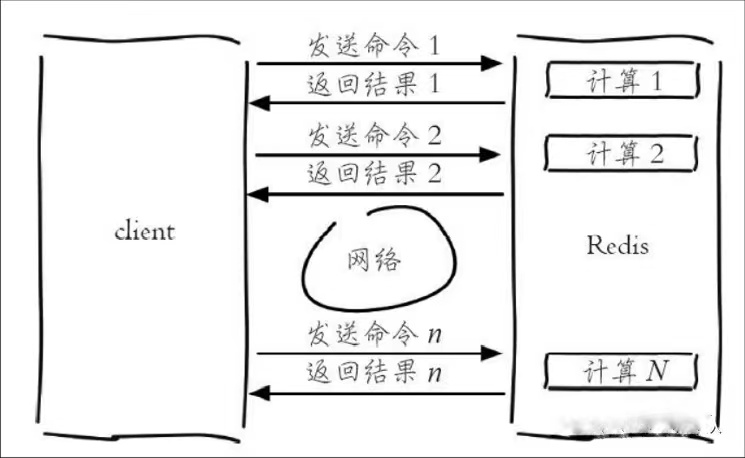
Redis 提供了一些批量操作命令(例如mget、mset等),有效地节约RTT。但大部分命令是不支持批量操作的,例如要执行 n 次 hgetall 命令,并没有 mhgetall 命令存在,需要消耗 n 次 RTT。
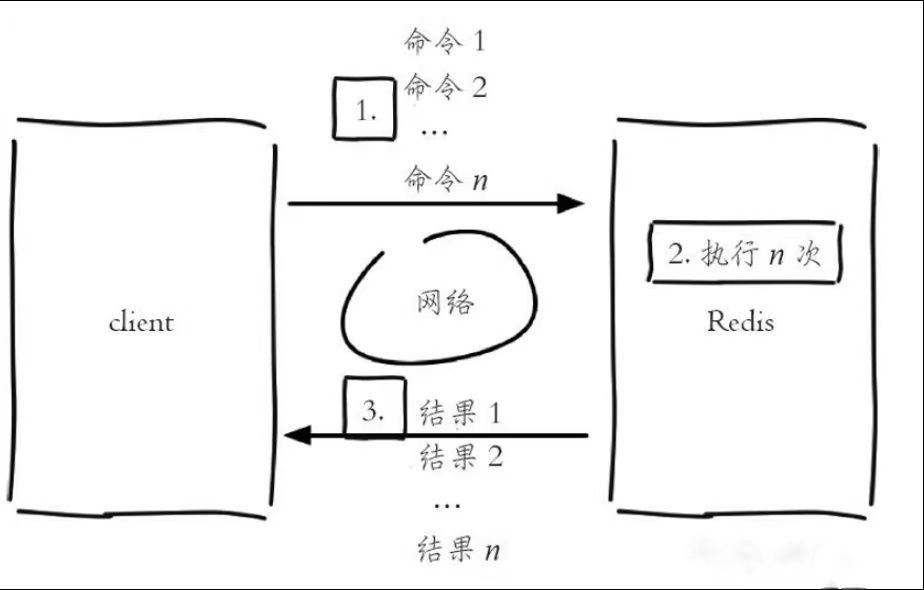
Redis 的客户端和服务端一般部署在不同的机器上。例如客户端请求服务器的 RTT(往返时延)为13 毫秒,那么客户端在 1 秒内只能执行 80 次左右的命令,这个和 Redis 的高并发高吞吐特性背道而驰。Pipeline(流水线)机制能改善上面这类问题,它能将一组 Redis 命令进行组装,通过一次网络请求传输给 Redis,再将这组 Redis 命令的执行结果按顺序返回给客户端。
不使用 Pipeline 的命令执行流程:
使用 Pipeline 的命令执行流程:
下面使用 Spring Data 提供的 redisTemplate 写一个示例:
public List testPipeline(){
List list = redisTemplate.executePipelined(new SessionCallback<Object>() {
@Override
public <K, V> Object execute(RedisOperations<K, V> operations) throws DataAccessException {
ValueOperations<String, Object> valueOperations = (ValueOperations<String, Object>) operations.opsForValue();
valueOperations.set("yzh1", "hello world");
valueOperations.set("yzh2", "redis");
valueOperations.get("yzh1");
valueOperations.get("yzh2");
return null; // 返回null即可,因为返回值会被管道的返回值覆盖,外层取不到这里的返回值
}
});
return list;
}发布订阅
发布订阅(pub/sub)是一种消息通信模式:发送者发送消息,订阅者接收消息。使用pub/sub主题订阅者模式,可以实现 1:N 的消息队列。
Redis客户端可以订阅任意数量的频道。发布的消息不会持久化,没有订阅者时候,发布消息会丢失,当在发布消息之后对channel进行订阅不会收到之前发布的消息。
常用命令:
SUBSCRIBE channel... # 订阅指定的一个/多个频道
PSUBSCRIBE pattern... # 订阅指定的一个/多个模式的频道
PUBLISH channel message # 将消息发布到指定频道
UNSUBSCRIBE channel... # 退订给定的频道
PUNSUBSCRIBE pattern... # 退订指定模式的频道订阅模式频道:
每个模式以* 作为通配符, 比如 user* 表示订阅所有以user开头的频道(如 user.log、user.news、user.message….)
Stream
Redis Stream 是 Redis 5.0 版本新增加的数据结构。Redis Stream 主要用于消息队列(MQ),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
GEO 地理位置
Redis 提供了 GEO(地理信息定位)功能,支持存储地理位置信息,用来实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能。
GEO 相关的命令如下:
# 用于添加城市的坐标信息:longitude、latitude、member分别是该地理位置的经度、纬度、成员
geoadd cities:locations 117.12 39.08 tianjin 114.29 38.02 shijiazhuang
# 获取地理位置信息
geopos key member [member ...]
# 获取两个坐标之间的距离,unit代表单位:m 米,km 千米
geodist key member1 member2 [unit]
# 获取指定位置范围内的地理信息位置集合,此命令可以用于实现附近的人的功能
georadius key longitude latitude radiusm
georadiusbymember key member radiusm
# 获取geo hash
geohash key member [member ...]
# 删除操作,GEO没有提供删除成员的命令,但是因为GEO的底层实现是zset,所以可以借用zrem命令实现对地理位置信息的删除。
zrem key member georadius 和g georadiusbymember两个命令的作用是一样的,都是以一个地理位置为中心算出指定半径内的其他地理信息位置,不同的是georadius命令的中心位置给出了具体的经纬度,georadiusbymember只需给出成员即可。其中radiusm|km|ft|mi是必需参数,指定了半径(带单位),这两个命令有很多可选参数,参数含义如下:
- withcoord:返回结果中包含经纬度。
- withdist:返回结果中包含离中心节点位置的距离。
- withhash:返回结果中包含geohash,有关geohash后面介绍。
- COUNT count:指定返回结果的数量。
- asc|desc:返回结果按照离中心节点的距离做升序或者降序。
- store key:将返回结果的地理位置信息保存到指定键。
- storedist key:将返回结果离中心节点的距离保存到指定键。
Redis使用geohash将二维经纬度转换为一维字符串,geohash有如下特点:
- GEO的数据类型为zset,Redis将所有地理位置信息的geohash存放在zset中。
- 字符串越长,表示的位置更精确,表3-8给出了字符串长度对应的精度,例如geohash长度为9时,精度在2米左右。
- 两个字符串越相似,它们之间的距离越近,Redis利用字符串前缀匹配算法实现相关的命令。
geohash编码和经纬度是可以相互转换的。- Redis正是使用有序集合并结合geohash的特性实现了GEO的若干命令。
HyperLogLog
HyperLogLog,它是 LogLog 算法的升级版,作用是能够在大数据中做高效率的基数统计(去重计数)。
有如下特点:
- 能够使用极少的内存统计海量数据,在Redis中实现的 HyperLogLog ,只需要12K 内存就可以统计2^64^个数据。
- 基数统计存在一定误差,标准误差率低于1%(0.81%)。
- 误差可以通过 辅助计算因子进行降低。
LogLog 算法
基数估计算法(LogLogCounting)是基于概率论与数理统计所设计的概率统计算法,用于在大数据中进行不完全精确的基数统计。
为什么叫LogLog 算法呢?因为这种算法的**空间复杂度是O(log(log(Nmax)))**,可以通过KB级内存估计数亿级别的基数。
有一个网站,可以动态地让你观察到 HyperLogLog 的算法到底是怎么执行的:

位图BitMap
许多开发语言都提供了操作位的功能,合理地使用位能够有效地提高内存使用率和开发效率。Redis提供了Bitmaps这个类型可以实现对位的操作:
- Bitmaps本身不是一种数据结构,它实际上是字符串,但是它可以对字符串的位进行操作。
- Bitmaps单独提供了一套命令,所以在 Redis 中使用 Bitmaps 和使用字符串的方法不太相同。可以把Bitmaps 想象成一个以位为单位的数组,数组的每个单元只能存储 0 和 1,数组的下标在 Bitmaps 中叫做偏移量。
在我们平时开发过程中,会有一些 bool 型数据需要存取,比如用户一年的签到记录, 签了是 1,没签是 0,要记录 365 天。如果使用普通的 key/value,每个用户要记录 365 个,当用户上亿的时候,需要的存储空间是惊人的。为了解决这个问题,Redis 提供了位图数据结构,这样每天的签到记录只占据一个位, 365 天就是 365 个位,46 个字节 (一个稍长一点的字符串) 就可以完全容纳下,这就大大节约了存储空间。
语法:
setbit key offset value # 设置或者清空 key 的 value(字符串)在 offset 处的 bit 值
getbit key offset # 返回 key 对应的 string 在 offset 处的 bit 值
bitcount key [start end] # start end 范围内被设置为1的数量,不传递 start end 默认全范围使用案例,统计用户登录(活跃)情况
# userId=001的用户登录,这是今天登录的第一个用户。
setbit userLogin:2021-03-10 001 1
# userId=002的用户登录,这是今天第二个登录的用户。
setbit userLogin:2021-03-10 002 1
# 查询用户002在2021-04-10 有没有登录
getbit userLogin:2021-03-10 002
# 统计2021-03-10当天登录系统的用户数量
bitcount active:2021-03-10 由于 bit 数组的每个位置只能存储 0 或者 1 这两个状态;所以对于实际生活中,处理两个状态的业务场景就可以考虑使用 bitmaps。如用户登录/未登录,签到/未签到,关注/未关注,打卡/未打卡等。同时 bitmap 还通过了相关的统计方法进行快速统计。
布隆过滤器
布隆过滤器(Bloom Filter)是1970年布隆提出来的。它实际上是一个很长的二进制向量和一系列随机映射函数(哈希函数)。
布隆过滤器用于检索一个元素是否在一个集合中。它的优点是空间和时间效率都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
应用场景
- 大数据中判断某个元素是否存在
- 解决缓存穿透
- 爬虫、邮箱系统的过滤
平时有没有注意到一些正常的邮件也会被放进垃圾邮件目录中,这就是布隆过滤器的误判导致的。
Redis 布隆过滤器
RedisBloom 在Redis4.0 中以插件的形式提供布隆过滤器功能,布隆过滤器是一个概率数据结构。
BloomFilter 有两个基本操作,即 bf.add 添加元素和 bf.exists 查询元素。
如果使用 BloomFilter 之前不指定过滤器,那么会使用Redis默认的布隆过滤器,Redis 也提供自定义参数的布隆过滤器。只需要在 bf.add 之前使用 bf.reserve 指令显示的创建自定义布隆过滤器;
bf.reserve 有三个参数: key , error_rate , initial_size;
- error_rate 错误率越低,需要的空间越大;对于不需要过于精确的场合,设置稍大一些也没有关系。
- initial_size 表示初始化大小,当实际数量超过这个值时,错误率就会上升。
如果不使用自定义布隆过滤器, 默认的配置 error_rate= 0.01 ,initial_size =100 ;布隆过滤器支持 add 和 isExist 操作,不支持 delete 操作
布隆过滤器判断
当mightContain() 方法返回 true 时,则该元素有99%的可能性在布隆过滤器中;
当mightContain() 方法返回 false 时,则该元素100% 不在布隆过滤器中;
注:Google的核心类库Guava也实现了布隆过滤器BloomFilter功能。
内部编码
Redis 的数据类型有:string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)等。但这些只是Redis 对客户端的数据类型,实际上每种数据类型都有自己底层的内部编码实现,而且是多种实现, Redis 会在适当的场景选择合适的内部编码。

注:上图中关于list的内部编码在Redis 3.2 版本中已经进行优化,使用quicklist 作为list 的内部编码;
可以看到每种数据结构都有多种内部编码实现,例如 字符串类型包含了 embstr raw int 三种内部编码。同时,有些内部编码如 ziplist, 可以作为多种外部数据结构的内部实现,可以通过 object encoding 命令查询内部编码。
Redis 所有的数据结构都是以唯一的字符串key 作为名称,然后通过key 来获取相应的 value 数据。不同类型的数据结构的差异就在于 value 的结构不一样。
Redis这样设计有两个好处:
- 在不影响对外数据结构和命令的情况下改进内部编码,这样一旦开发出更优秀的内部编码,无需改动外部数据结构和命令。
这种设计理念和编程中的抽象接口与实现类是一样的,我们定义一个接口,但可以有多种不同的实现。 - 多种内部编码实现可以在不同场景下发挥各自的优势。例如ziplist比较节省内存,但是在列表元素比较多的情况下,性能会有所下降,这时候Redis会根据配置选项将列表类型的内部实现转换为其他数据结构。
整体存储结构
在学习底层数据存储结构之前,首先看下redis整体的存储结构。redis内部整体的存储结构是一个大的hashmap,内部是数组+链表的方式实现,通过拉链法解决hash冲突,每个dictEntry为一个key/value对象,value为定义的redisObject。
结构图如下:

接着再往下看redisObject究竟是什么结构

*ptr指向具体的数据结构的地址。type表示该对象的类型,即String,List,Hash,Set,Zset中的一个,但为了提高存储效率与程序执行效率,每种对象的底层数据结构实现都可能不止一种。encoding表示对象底层所使用的编码。
下面会分别介绍5种数据结构的内部编码方式。
String
字符串类型的内部编码有三种,Redis会根据当前值的类型和长度决定使用何种内部编码实现:
- embstr:不大于44个字节的短字符串。
- raw:大于44个字节的长字符串。
- int:8个字节的长整型。
示例:
# 短字符串使用embstr编码
> set a_string_short aaaaaaaaaa-aaaaaaaaaa-aaaaaaaaaa-aaaaaaaaaa-
OK
> STRLEN a_string_short
(integer) 44
> object encoding a_string_short
"embstr"
# 当字符串长度大于44时就变成了raw
> set b_string_short aaaaaaaaaa-aaaaaaaaaa-aaaaaaaaaa-aaaaaaaaaa-a
OK
127.0.0.1:6379> STRLEN b_string_short
(integer) 45
127.0.0.1:6379> object encoding b_string_short
"raw"redisObject 和 sdshdr8 结构体:

为什么会是44个字节呢?
在64位操作系统中,cpu缓存行大小占64byte,而 redisObject 和 sdshdr8 正好占用20个字节,所以当业务数据大小在64-20=44字节之内的话,可以利用cpu缓存行特性:操作系统分配内存的时候,就会挨着redisObject进行分配,开辟一块连续的空间存储,利用cpu的缓存行一次读取到数据,减少内存IO,这样整个数据就在cpu缓存行范围内,在进行数据读取的时候,通过redisObject我们可以直接拿到值,而不用通过指针再一次寻址去拿数据,这就是embstr做的事情。
此外,使用append 等命令会修改redis内部编码,就不适用cpu缓存行优化的方式了:
> set a a
OK
> object encoding a
"embstr"
> append a b
(integer) 2
> object encoding a
"raw"raw 编码
# 长字符串使用raw编码
set str "The sun is at the end of the mountain, the Yellow River flows into the sea"
object encoding str # "raw" int 编码
当键值内容可以用一个64位有符号整数表示时,Redis会将键值转换成long类型来存储。如SET key 123456,实际占用的空间是sizeof(redisObject) 为16字节,比存储 “foobar” 节省了 一半的存储空间。
# 整型类型使用int编码
set str 1234567
object encoding str # "int" 注:
string 类型使用的内部编码是固定规则,不能通过配置文件去修改规则。其他四种类型都可以在配置文件中修改内部编码规则。
Hash
哈希类型的内部编码有两种:
ziplist(压缩列表):当散列类型键的字段个数少于
hash-max-ziplist-entries参数值(默认512个)且每个字段名和字段值的长度都小于hash-max-ziplist-value参数值(默认64个字节)时,Redis会使用ziplist作为哈希的内部实现。ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比 hashtable 更加优秀。hashtable(哈希表):当无法满足以上条件时,Redis会使用 hashtable作为哈希的内部实现。因为当数据量变大时 ziplist的读写效率会下降,而hashtable 的读写时间复杂度为O(1)。
示例:
# 当field个数比较少且没有大的value时,内部编码为ziplist
hmset user:1 name kebi age 26
object encoding user:1 # "ziplist"
# 当有value大于64个字节,内部编码会由ziplist变为hashtable
hmset user:1 info "The sun is at the end of the mountain, the Yellow River flows into the sea"
object encoding user:1 # "hashtable"
# 当field个数超过512,内部编码也会由ziplist变为hashtable
...注意:当一个哈希的编码由ziplist变为hashtable的时候,即使在替换掉所有值,它也一直都会是hashtable类型,不会转化为ziplist。
与Hash内部编码相关的配置项:
# hash类型使用ziplist编码时,字段的最大个数
hash-max-ziplist-entries 512
# hash类型使用ziplist编码时,每个字段名和字段值的最大长度(字节)
hash-max-ziplist-value 64 List
Redis 3.2之前的版本 ,列表类型的内部编码有两种:
ziplist(压缩列表):如果列表的元素个数小于512个,同时每个元素的值小于64字节时 ,采用ziplist为内部编码保存。
linkedlist(链表):以上条件无法满足时,Redis会使用 linkedlist作为列表的内部实现。
ziplist 结构:

ziplist数据结构说明:
- zlbytes:32bit表示ziplist占用的字节总数
- zltail:32bit表示ziplist表中最后一项entry在ziplist中的偏移字节数。通过zltail我们可以很方便地找到最后一项,从而可以在ziplist尾端快速地执行push或pop操作
- zlen:16bit表示ziplist中数据项entry的个数
- entry:表示真正存放数据的数据项,长度不定
- zlend:ziplist最后一个字节,是一个结束标记,值固定等于255
- prerawlen:前一个entry的数据长度
- len:entry中数据的长度
- data:真实数据存储
为了节省内存空间,ziplist是非常紧凑的一种数据类型。而非常紧凑的数据结构的缺点是:
- 空间必须是连续的
- 数据量非常大的时候往里面加元素,数据迁移很麻烦
- 频繁的内存分配与释放是不划算的,所以redis针对这个问题进行了优化,提供了quicklist
Redis3.2版本提供了quicklist 编码,快速列表是ziplist和linkedlist的混合体,是将linkedlist按段切分,每一段用ziplist来紧凑存储,多个ziplist之间使用双向指针链接,它结合了ziplist和linkedlist两者的优势。
为什么不直接使用linkedlist?
linkedlist的附加空间相对太高,prev和next指针就要占去16个字节,而且每一个结点都是单独分配,会加剧内存的碎片化,影响内存管理效率。

示例:
> lpush queue-task a b c
OK
> type queue-task
list
> object encoding queue-task
"quicklist"ziplist容量
quicklist内部默认单个ziplist长度为8kb,超出了这个字节数,就会新建一个ziplist。关于长度可以使用list-max-ziplist-size 设置。
list-max-ziplist-size 配置项用于指定list中单个 ziplist 的最大容量,官方给出以下几种选项:
- -5: 最大 64 Kb <–不推荐用于正常工作负载
- -4: 最大: 32 Kb <– 不推荐
- -3: max size: 16 Kb <– 不推荐
- -2: max size: 8 Kb <– 推荐
- -1: max size: 4 Kb <– 推荐
默认选项为 -2,官方认为性能最高的选项通常是 -2(8 Kb 大小)或 -1(4 Kb 大小);
压缩深度
上面说到了quicklist下是用多个ziplist组成的,同时为了进一步节约空间,Redis还会对ziplist进行压缩存储,可以选择压缩深度。list-compress-depth 配置项用于设置 quickList的数据压缩范围,提升数据存取效率:
- 0:默认不压缩
- 1:表示不压缩头尾节点,压缩中间数据 (为了支持快速push/pop操作)
- 2:表示头尾节点和头尾相邻的一个节点不压缩,压缩除此之外中间的
- 3:表示头尾节点和头尾相邻的两个节点不压缩,压缩除此之外中间的
- …:依次类推
# 单个 ziplist 的最大容量(默认8Kb)
list-max-ziplist-size -2
# 数据压缩范围(默认不压缩)
list-compress-depth 0Set
集合类型的内部编码有两种:
intset(整数集合):当集合中的元素都是整数且元素个数小于
set-max-intset-entries配置(默认512个)时,Redis会选用intset来作为集合内部实现,从而减少内存的使用。hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用 hashtable作为集合的内部实现。
示例:
# 当元素个数较少且都为整数时,内部编码为intset:
sadd setkey 2 3 4 5
object encoding setkey # "intset"
# 当元素个数超过512个,内部编码变为hastable:
sadd setkey2 1 2 3 ... 513
object encoding setkey2 #"hashtable"
# 当某个元素不为整数时,内部编码为hashtable:
sadd setkey3 a b c
object encoding setkey2 #"hashtable"与ZSet内部编码相关的配置项:
# set类型使用intset编码的最大元素个数(必须为整数)
set-max-intset-entries 512ZSet
有序集合类型的内部编码有两种
- ziplist(压缩列表):当有序集合的元素个数小于
zset-max-ziplist-entries配置(默认128个)
同时每个元素的值小于zset-max-ziplist-value配置(默认64个字节)时,Redis会用ziplist来作为有序集合的内部实现, ziplist可以有效减少内存使用。
- skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作为内部实现,因为此时ziplist 的读写效率会下降。
示例:
# 当元素个数较少且每个元素较小时,内部编码为ziplist:
zadd zsetkey 50 a 60 b 30 c
object encoding zsetkey # "ziplist"
# 当元素个数超过128个,内部编码变为skiplist:
zadd zsetkey 1 2 3 ... 129
object encoding zsetkey # "skiplist"
# 当某个元素大于64个字节时,内部编码也会变为skiplist:
zadd zsetkey 50 a "The sun is at the end of the mountain, the Yellow River flows into the sea"
object encoding zsetkey # "skiplist"与ZSet内部编码相关的配置项:
# zset类型使用ziplist编码的最大元素个数
zset-max-ziplist-entries 128
# zset类型使用ziplist编码时,单个元素的最大容量(字节)
zset-max-ziplist-value 64 数据备份与恢复
Redis 服务支持数据持久化。
RDB与AOF同时开启 默认先加载AOF的配置文件;4.0+的可以使用RDB-AOF混合持久化格式。
RDB 内存快照
将某一时刻的内存数据,以二进制文件的形式写入磁盘。
手动执行方式
手动通过命令执行数据持久化:
# 同步保存数据到磁盘
127.0.0.1:6379> save
OK
# 异步保存数据到磁盘
127.0.0.1:6379> bgsave
Background saving started注:
bgsave 是Redis通过调用 fork 来创建一个子进程,子进程负责快照写入磁盘,而父进程仍然继续处理命令;
save 则是同步持久化数据,save 命令执行过程中,Redis不能响应其他任何命令;
配置文件方式
在redis.conf中设置save配置选项(常用)
save 900 1
save 300 10
save 60 10000 上面是Redis默认的配置信息,表示 900s (15min) 内至少发生1次写操作,则触发异步持久化; 300s (5min) 内至少发生10次写操作,则触发异步持久化; 60s (1min) 内至少发生10000次写操作,则触发异步持久化;
任何一条满足,都会触发异步持久化( BGSAVE 操作),在根目录生成持久化文件。
和RDB 相关的配置还有如下
# RDB 文件名
dbfilename dump.rdb
# RDB 文件目录
dir ./
# bgsave 失败之后,是否停止持久化数据到磁盘,yes 表示停止持久化,no 表示忽略错误继续写文件。
stop-writes-on-bgsave-error yes
# RDB 文件压缩
rdbcompression yes
# 写入文件和读取文件时是否开启 RDB 文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。
rdbchecksum yesRDB 文件恢复
当Redis 服务器启动时,如果根目录存在RDB文件 dump.rdb,Redis就会自动加载RDB文件还原持久化数据,如果根目录没有,请先将dump.rdb文件移动到Redis根目录。
优缺点
- RDB文件的内容为二进制数据,占用内存更小,更适合做备份文件。
- RDB 对灾难恢复很有用,它是一个紧凑的文件,可以更快的传输到远程服务器进行数据恢复。
- RDB可以更大程度的提高Redis的运行速度,因为每次持久化时主进程会fork 一个子进程进行工作,Redis主进程并不会执行磁盘IO操作。
- 与AOF格式的文件相比,RDB文件可以更快的重启。
缺点:
- 在意外宕机情况下,RDB文件会丢失一部分数据。(RDB保存的是某一时刻的内存数据)
- 数据量很大时,持久化很耗时;
AOF 日志文件
AOF 持久化方式默认是关闭的。
在执行写命令时,AOF 会将写的命令追加到AOF文件的末尾,以此记录数据的变化。
# redis默认关闭AOF机制,可以将no改成yes实现AOF持久化
appendonly no
# AOF文件名
appendfilename "appendonly.aof"
# AOF持久化同步频率
# appendfsync always always表示每次写数据都要同步到磁盘,此方式会降低Redis的性能,不建议开启
appendfsync everysec # everysec表示每秒执行一次同步
# appendfsync no # no表示让操作系统来决定应该何时进行同步fsync,Linux系统往往可能30秒才会执行一次rewrite
混合持久化
Redis4.0 新增的特性,混合持久化方式结合了RDB和AOF 的优点,
# 开启混合持久化
aof-use-rdb-preamble yes正常、异常关闭服务
当Redis通过shutdown命令关闭服务器请求时,会执行 SAVE 命令创建一个快照,如果使用 kill -9 PID 将不会创建快照。
服务高可用
多台服务器组成的集群自然要比单台服务器的可用性更高,Redis 支持三种集群部署模式:
- 主从模式 Master-Salve
- 哨兵模式 Sentinel
- 集群模式 Cluster
主从复制(Master-Slave)
客户端向主服务器(Master)写入数据,自动同步到从服务(Slave)上。
Redis的主从复制是异步复制,异步分为两个方面,一个是master服务器在将数据同步到slave时是异步的,因此master服务器在这里仍然可以接收其他请求,一个是slave在接收同步数据也是异步的。
优点:
- 读写分离,负载均衡。主节点负载读写,从节点负责读,提高服务器并发量
- 故障恢复,避免单点故障带来的服务不可用
- 高可用基础,是哨兵机制和集群实现的基础
配置主从复制
Redis的主从配置非常简单,我们假设Redis的master服务器地址为192.168.0.101。
slave服务器配置主服务器
slaveof 192.168.1.101 6379可以用户命令info replication查看复制信息
Slave默认为只读的
在Redis2.6以后,slave只读模式是默认开启的,我们可以通过配置文件中的slave-read-only选项配置是否开启只读模式:
# 默认是yes
slave-read-only yes/no 复制验证
如果我们需要slave对master的复制进行验证,可以在master中配置requirepass <password>选项设置密码
那么需要在从服务器中使用该密码,可以使用命令config set masterauth <password>,或者在配置文件中设置masterauth <password>
哨兵模式(Sentinel)
在主从模式下,如果Master 宕机,可以将一个Slave 升级为主服务器,以便继续提供服务,但这个过程需要人工手动处理。为此,Redis提供哨兵模式来实现自动化的系统监控和故障恢复功能。
哨兵模式主要做两件事:
- 监控Master 和 Slave 是否正常运行;
- Master 故障后自动将一个 Slave 升级为主服务器;
哨兵模式是基于主从复制的,主从复制的优点,哨兵模式都具备。
集群模式(Cluster)
Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。Redis Cluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储。
Redis Cluster 是 Redis 的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 分布式方面的需求。
Redis Cluster 节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为主节点,三个为从节点。三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点。

如上图所示,该集群中包含 6 个 Redis 节点,3主3从,分别为M1,M2,M3,S1,S2,S3。除了主从 Redis 节点之间进行数据复制外,所有 Redis 节点之间采用 Gossip 协议进行通信,交换维护节点元数据信息。
一般来说,主 Redis 节点会处理 Clients 的读写操作,而从节点只处理读操作。
Cluster 与主从复制和哨兵的主要区别是,哨兵和主从复制模式的每个节点都是全量数据的存储,而Cluster 可以将数据分布式存储,即每个节点存储的数据都不一样。
Redis-Cluster 采用无中心化的结构,特点如下:
- 所有的Redis节点彼此互联,可以通信;
- 节点的fail 是通过集群中超过半数的节点检测失败时才生效;
- 客户端只需要连接Redis集群中任意一个节点即可,不需要中间层代理,不需要连接所有节点;
使用集群,只需要将每个数据库节点的 cluster-enable 配置打开即可。每个集群中至少需要三个主数据库才能正常运行。
cluster-enabled yes # 开启集群
cluster-config-file nodes-6382.conf # 指定集群配置文件名Gossip 通信机制
为了让让集群中的每个实例都知道其他所有实例的状态信息,Redis 集群规定各个实例之间按照 Gossip 协议来通信传递信息。
1)消息的延迟
由于 Gossip 协议中,节点只会随机向少数几个节点发送消息,消息最终是通过多个轮次的散播而到达全网的,因此使用 Gossip 协议会造成不可避免的消息延迟。不适合用在对实时性要求较高的场景下。
2)消息冗余
Gossip 协议规定,因此就不可避免的存在消息重复发送给同一节点的情况,造成了消息的冗余,同时也增加了收到消息的节点的处理压力。而且,由于是定期发送,因此,即使收到了消息的节点还会反复收到重复消息,加重了消息的冗余。
分布式锁
在许多场景下,不同的进程需要对共享资源以互斥的方式访问,以保证数据安全,分布式锁便是强有力的保障。
单节点Redis分布式锁
整个逻辑就是,让所有想操作「共享资源」的客户端都去 Redis 中 SETNX 同一条数据,谁先添加成功谁就算拥有分布式锁,然后就可以操作「共享资源」,操作完后在删掉该数据,释放锁。
加锁
SET lock_key $unique_id EX 30 NX注:
NX 的意思是不存在时才会设置它的值,否则什么也不做,这保证读改写3个操作在Redis服务器中是原子操作;
设置过期时间30S,是为了防止加锁成功后的客户端还没释放锁就自己宕机,导致锁无法释放;
设置的value是客户端自己知道的随机值或线程ID,其他客户端不知道,这样可以避免客户端释放不属于他的锁;
释放锁
示例:
EVAL ./release.lua 1 my:lock lock:394A23CC43release.lua 脚本:如果指定键的值与入参值相同,则删除该键值。
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end避免锁提前释放
到现在还有一个问题没解决,那就是如果业务执行时间超过锁的过期时间,锁就会在业务执行完之前提前释放,可能导致其他客户端也获取锁,造成线程不安全。
我们可以设计这样一个方案:加锁时,先设置一个过期时间,然后开启一个「守护线程」,定时去检测这个锁的过期时间,如果锁快要过期了,操作共享资源还未完成,那么就对锁进行「自动续期」,重新设置过期时间。如果你是 Java 技术栈,已经有一个 Redisson 库把这些工作都封装好了。
Redisson封装了很多易用的分布式功能:
- 可重入锁
- 乐观锁
- 公平锁
- 读写锁
- Redlock
多节点Redis分布式锁
集群下的问题
来看下面这个场景
- 客户端 1 在主库上执行 SET 命令,加锁成功
- 此时,主库异常宕机,SET 命令还未同步到从库上(主从复制是异步的)
- 从库被哨兵提升为新主库,这个锁在新的主库上,丢失了!
可以看到在主从切换时,上面的单节点解决方案是有问题的。Redis官方提供了一种规范的算法来实现Redis 多节点的分布式锁 RedLock 。
RedLock
RedLock 解决方案基于 2 个前提:
- 只使用主库,不需要从库和哨兵实例
- 主库要部署多个,官方推荐至少 5 个实例
也就是说,想用使用 Redlock,至少要部署 5 个 Redis 实例,而且都是主库,它们之间没有任何关系。
注:RedLock 不强调部署 Redis Cluster,部署 5 个不相关的 Redis 实例即可,当然RedLock 和集群部署也并不冲突。
Redlock 整个流程如下:
- 客户端先获取「当前时间戳 T1」
- 客户端依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),并设置超时时间(毫秒级),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
- 如果客户端从超过半数的 Redis 实例(>=3 )加锁成功,则再次获取「当前时间戳 T2」,判断如果锁的租期 > T2 - T1 ,则认为客户端加锁成功,否则认为加锁失败。
- 加锁成功后去操作共享资源。
- 加锁失败或操作结束,向「全部节点」发起释放锁请求(前面讲到的 Lua 脚本释放锁)
整个逻辑说白了就是大家都去抢注锁,谁抢注的多谁就拥有锁。Redlock 通过向当前存活的多个主库抢注锁,实现了即使部分节点不可用,也不会影响到分布式锁系统,解决主从切换时,锁丢失的问题。
注意 Redlock 依然需要搭配 Redisson 来解决锁提前释放的问题
RedLock的争议
那么 Redlock 真的绝对安全吗?有人并不这么认为。Redis 作者提出的 Redlock 方案后,马上受到英国剑桥大学、业界著名的分布式系统专家 Martin (《数据密集型应用系统设计》作者)的质疑!认为这个 Redlock 的算法模型是有问题的,并写了篇文件对分布式锁的设计,提出了自己的看法。
之后,Redis 作者 Antirez 面对质疑,不甘示弱,也写了一篇文章,反驳了对方的观点,并详细剖析了 Redlock 算法模型的更多设计细节。关于争议的具体细节不在本文详细描述了,但强烈建议大家去仔细读一读,看看神仙是怎么“打架”的。
最后比较中肯的结论是,无论是 RedLock还是其他分布式锁的算法,在极端情况下都有可能出现问题, 只要明确极端情况下应该怎么提前采取措施避免,RedLock 当然是可以使用的。印证了那句话,在软件领域,没有一个解决方案是万能通用的,只有在不同的场景下选择合适的解决方案。同时,对于分布式锁的争议本身这件事,也会加深我们对分布式锁的理解。
运维
# 连接服务器
redis-cli -h host -p 3679 -a password
# 切换数据库,默认为0
select 1
DBSIZE # 返回当前数据库中 key 的数量
FLUSHDB # 删除当前数据库的所有key
FLUSHALL # 删除所有数据库的所有key
COMMAND COUNT # 获取 Redis 命令总数
COMMAND # 获取 Redis 命令详情
SAVE # 同步保存数据到硬盘
# 注册服务
redis-server --service-install redis.windows.conf
# 删除服务
redis-server --service-uninstall
# 开启服务
redis-server --service-start
# 停止服务
redis-server --service-stop配置文件
Redis 修改服务器配置的方式有2种:
- 使用
config set命令的方式修改配置; - 修改Redis的配置文件
redis.conf;
注意:
命令方式会立即生效,但下次服务重启会失效;而修改配置文件不会立即生效,必须服务器重启后才能生效;
实际使用中两者可以相结合使用。
redis.conf 配置文件
官方配置文件参考:http://download.redis.io/redis-stable/redis.conf
# 修改为守护进程模式; Redis默认不是以守护进程的方式运行,使用yes启用守护进程
daemonize yes
# 绑定的主机地址
bind 127.0.0.1
# 端口号
port 6379
# 当客户端闲置多长时间断开连接;如果配置0则关闭该功能
timeout 300
# 指定在多长时间内,有多少次变化,才将数据同步到磁盘,可以多个条件配合
save <seconds> <changes>
save 900 1 # 900秒(15分钟)内有1次写操作,数据同步到磁盘
save 300 10 # 300秒(5分钟)内有10次写操作,数据同步到磁盘
save 60 10000 # 60秒内有10000次写操作,数据同步到磁盘
# 指定RDB数据库文件的名称
dbfilename dump.rdb
# 指定RDB文件的存放目录
dir ./
# 数据持久化到RDB文件是否压缩数据,默认yes;如果为了节省CPU时间可以关闭,但会导致RDB数据库文件变大;
rdbcompression yes
# 是否每次写操作就进行日志记录(异步),默认no; 如果突然宕机,Redis有可能丢失一部分数据;
appendonly no
# 指定更新日志条件,有3个可选值
appendfsync everysec
no # 表示等待操作系统将数据同步到磁盘(快)
always # 每次写操作都会调用fsync将数据同步到磁盘(慢,影响性能)
everysec # 表示每秒同步一次;(折中,默认值)
# 指定日志文件名称,默认appendonly.aof
appendfilename appendonly.aof
# 设置当前主机为slave时,设置master的ip和port; Redis启动时,自动从master进行数据同步;
slaveof <masterip> <masterport>
# 当 master 服务设置了密码保护时,slav 服务连接 master 的密码
masterauth <master-password>
# 设置 Redis 连接密码,如果配置了连接密码,客户端在连接 Redis 时需要通过 AUTH <password> 命令提供密码,默认关闭
requirepass foobared
# 设置 Redis 最大内存限制;达到最大内存后,数据将无法进行写操作,但可以进行读操作;
maxmemory <bytes>| daemonize | yes、no | yes表示启用守护进程,默认是no即不以守护进程方式运行。其中Windows系统下不支持启用守护进程方式运行 |
|---|---|---|
| port | 指定 Redis 监听端口,默认端口为 6379 | |
| bind | 绑定的主机地址,如果需要设置远程访问则直接将这个属性备注下或者改为bind * 即可,这个属性和下面的protected-mode控制了是否可以远程访问 | |
| protected-mode | yes 、no | 保护模式,该模式控制外部网是否可以连接redis服务,默认是yes,所以默认我们外网是无法访问的,如需外网连接rendis服务则需要将此属性改为no |
| loglevel | debug、verbose、notice、warning | 日志级别,默认为 notice |
| databases | 16 | 设置数据库的数量,默认的数据库是0。整个通过客户端工具可以看得到 |
| rdbcompression | yes、no | 指定存储至本地数据库时是否压缩数据,默认为 yes,Redis 采用 LZF 压缩,如果为了节省 CPU 时间,可以关闭该选项,但会导致数据库文件变得巨大 |
| dbfilename | dump.rdb | 指定本地数据库文件名,默认值为 dump.rdb |
| dir | 指定本地数据库存放目录 | |
| requirepass | 设置 Redis 连接密码,如果配置了连接密码,客户端在连接 Redis 时需要通过 AUTH命令提供密码,默认关闭 | |
| maxclients | 0 | 设置同一时间最大客户端连接数,默认无限制,Redis 可以同时打开的客户端连接数为 Redis 进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis 会关闭新的连接并向客户端返回 max number of clients reached 错误信息 |
| maxmemory | XXX | 指定 Redis 最大内存限制,Redis 在启动时会把数据加载到内存中,达到最大内存后,Redis 会先尝试清除已到期或即将到期的 Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis 新的 vm 机制,会把 Key 存放内存,Value 会存放在 swap 区。配置项值范围列里XXX为数值 |
配置命令
使用 CONFIG SET parameter value 和 CONFIG GET parameter 命令操作配置参数:
# 获取某参数的配置信息
127.0.0.1:6379> config get port
1) "port"
2) "6379"注:命令方式修改 redis 配置参数,无需重启就会生效,但服务器重启会失效,配合配置文件一起使用。
慢查询分析
许多存储系统(例如MySQL)提供慢查询日志帮助开发和运维人员定位系统存在的慢操作。所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阈值,就将这条命令的相关信息(例如:发生时间,耗时,命令的详细信息)记录下来,Redis 也提供了类似的功能。
对于慢查询功能,需要明确 3 件事:
1、预设阈值怎么设置?
在 redis 配置文件中修改配置 ‘slowlog-log-slower-than’ 的值,单位是微妙(1秒 = 1000毫秒 = 1000000微秒),默认是 10000 微秒,如果把 slowlog-log-slower-than 设置为 0,将会记录所有命令到日志中。如果把 slowlog-log-slower-than 设置小于0,将会不记录任何命令到日志中。
2、慢查询记录存放在哪?
在 redis 配置文件中修改配置 ‘slowlog-max-len’ 的值。slowlog-max-len 的作用是指定慢查询日志最多存储的条数。实际上,Redis 使用了一个列表存放慢查询日志,slowlog-max-len 就是这个列表的最大长度。当一个新的命令满足满足慢查询条件时,被插入这个列表中。当慢查询日志列表已经达到最大长度时,最早插入的那条命令将被从列表中移出。比如,slowlog-max-len 被设置为 10,当有第11条命令插入时,在列表中的第1条命令先被移出,然后再把第11条命令放入列表。
记录慢查询指 Redis 会对长命令进行截断,不会大量占用大量内存。在实际的生产环境中,为了减缓慢查询被移出的可能和更方便地定位慢查询,建议将慢查询日志的长度调整的大一些。比如可以设置为 1000 以上。
除了去配置文件中修改,也可以通过 config set 命令动态修改配置
> set slowlog-log-slower-than 1000
> config set slowlog-max-len 1200
> config rewrite3、如何获取慢查询日志?
可以使用 slowlog get 命令获取慢查询日志,在 slowlog get 后面还可以加一个数字,用于指定获取慢查询日志的条数,比如,获取2条慢查询日志:
> slowlog get 3
1) 1) (integer) 6107
2) (integer) 1616398930
3) (integer) 3109
4) 1) "config"
2) "rewrite"
2) 1) (integer) 6106
2) (integer) 1613701788
3) (integer) 36004
4) 1) "flushall"可以看出每一条慢查询日志都有4个属性组成:
- 唯一标识ID
- 命令执行的时间戳
- 命令执行时长
- 执行的命名和参数
此外,可以通过 slowlog len 命令获取慢查询日志的长度;通过 slowlog reset 命令清理慢查询日志。
README
作者:银法王
版权声明:本文遵循知识共享许可协议3.0(CC 协议): 署名-非商业性使用-相同方式共享 (by-nc-sa)
参考:
修改记录:
2020-02-26 第一次修订
2020-03-19 完善内容
2021-02-27 完善内容
2023-02-22 重构目录结构及内容